
Page 61 - 《应用声学》2020年第2期
P. 61
第 39 卷 第 2 期 褚钰等: 语音情感识别中的特征选择方法 219
化为一维列向量 M ,对 T 分别求取最大值、最小
′
3 实验测试
值、均值、标准差得到一维列向量T ,对F 分别求取
′
最大值、最小值、均值、标准差得到一维列向量 F , 3.1 数据集
′
由于 MFCC 特征是情感识别中较为有效的频谱特 本实验在 3 种语种的公开数据集上进行:中
征,在实验中表现稳定且在不同数据集上均具有较 国科学院汉语数据集、EmoV-DB 英语情感数据
高的识别率,因此在之后的操作中保留MFCC 的全 集 [22] 、德国柏林德语语料库 [23] 。
部 13 维特征,将之前得到的 T 和 F 添加到 M 之 汉 语 数 据 集 共 有 语 音 300 条, 采 样 频 率 为
′
′
′
后,即得到融合特征向量。 16 kHz,16 bit 量化,语音有 angry、fear、happi-
ness、neutral、sad、surprise 共 6 种情感,每种情感
100
BP 各 50 条语音;EmoV-DB 英语情感数据集共有语音
RF
80 SVM
1817 条,采样频率为 16 kHz,16 bit 量化,语音包含
គѿဋ/% 60 amused、angry、disgust、neutral、sleepiness 共 5 种
情感;德国柏林德语语料库中包含 7 种情感,共 535
40
句情感语音信号,本文从中选择了 angry、happy、
neutral、sad 四种情感,每种情感随机选择 60 条语
20
音,共 240 条用于识别,音频采样频率为 16 kHz,
0 16 bit量化。
MFCC MFCC_d MFCC_dd LOGMEL RPLP RPLP_d RPLP_dd FT ZCR STE FM FM1 FM2 本文共选择 2357 条语音用于构建实验数据集,
(a) ឦᬷ
总时长 2 h 50 min,其中训练集时长 2 h 16 min,包
100
BP 含语音1886条。
RF
80 SVM
3.2 实验设计
គѿဋ/% 60 部分:第一部分验证特征融合算法的有效性;第二部
为验证本文所提特征融合算法,实验分为两个
40
分验证本文所提融合特征较之于其他融合特征,具
20 有更稳定的识别能力。
在第一部分的实验中,选取 3 个数据集上具有
0
MFCC MFCC_d MFCC_dd LOGMEL RPLP RPLP_d RPLP_dd FT ZCR STE FM FM1 FM2 最好表现的声学特征:MFCC、基音频率、共振峰进
(b) ᔮឦᬷ 行融合。将得到的融合特征分别使用BP 神经网络、
随机森林、支持向量机 3 种算法在 3 个数据集上进
100
BP
RF 行情感识别,与 MFCC、基音频率、共振峰这 3 个单
80 SVM
一特征的识别率进行比较。在第二部分的实验中设
គѿဋ/% 60 计多组对照试验,随机选取3个特征进行融合并在 3
个数据集上进行情感识别,将得到的识别率与本文
40
提出的融合特征进行比较。
20
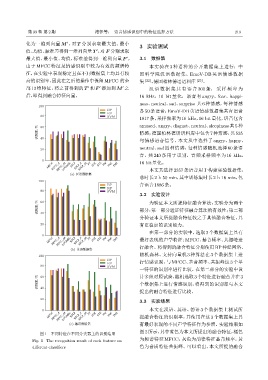
3.3 实验结果
0 本文在汉语、英语、德语 3 个数据集上测试所
MFCC MFCC_d MFCC_dd LOGMEL RPLP RPLP_d RPLP_dd FT ZCR STE FM FM1 FM2 提融合特征的识别率,并使用在这 3 个数据集上具
(c) ॴឦᬷ 有最好表现的不同声学特征作为参照。实验结果如
图 2 所示,其中蓝色为本文所提出的融合特征,橘色
图 1 不同特征在不同分类器上的识别结果
Fig. 1 The recognition result of each feature on 为频谱特征 MFCC,灰色为韵律特征基音频率,黄
different classifiers 色为音质特征共振峰。可以看出,本文所提的融合