
Page 76 - 《应用声学》2023年第2期
P. 76
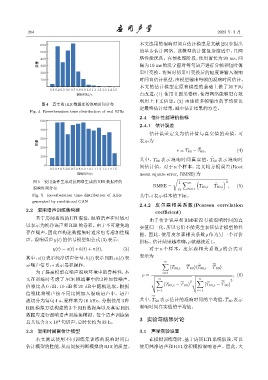
264 2023 年 3 月
本文选用的混响时间盲估计模型是文献[25]中提出
600
的单步估计网络。该模型的计算复杂度适中,且网
500
400 络性能优良。在预处理阶段,使用窗长为 20 ms、间
᧚ 300 隔为 10 ms的汉宁窗对每句语声进行分帧和短时傅
200 里叶变换。将短时傅里叶变换后的幅度谱输入混响
100 时间盲估计模型,由模型输出每帧的混响时间估计。
本文的估计模型在原有模型的基础上做了如下两
0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0 1.1 1.2 1.3 1.4 1.5
ຉ־ᫎ/s 点改进:(1) 使用非因果卷积,使得网络能够更有效
利用上下文信息。(2) 由连续多帧输出的平均值决
图 4 真实的 RIR 数据库的混响时间分布
定最终估计结果,减少估计结果的方差。
Fig. 4 Reverberation time distribution of real RIRs
2.4 估计性能评价指标
500
2.4.1 估计误差
400
估计误差定义为估计值与真实值的差值,可
᧚ 300 表示为
200
e = T 60 − T 60 , (4)
b
100
其中,T 60 表示混响时间真实值,T 60 表示混响时
b
0 间估计值。对于 n 个样本,定义均方根误差 (Root
0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0 1.1 1.2 1.3 1.4 1.5
ຉ־ᫎ/s mean square error, RMSE)为
√
图 5 使用条件生成对抗网络生成的 RIR 数据库的 1 ∑ n ( ) 2
RMSE = T 60,i − T 60,i , (5)
b
混响时间分布 n i=1
Fig. 5 Reverberation time distribution of RIRs 其中,i表示样本的下标。
generated by conditional GAN
2.4.2 皮 尔 森 相 关 系 数 (Pearson correlation
2.2 混响语声训练集构建 coefficient)
基于房间系统的 LTI 假设,混响语声在时域可 由于估计误差和 RMSE 没有被混响时间的真
以表示为纯净语声和RIR的卷积。由于不可避免地 实值归一化,所以它们不能完全表征估计模型的性
存在噪声,因此在构建数据集时通常也考虑加性噪
能。因此,使用皮尔森相关系数 ρ 作为另一个评价
声。混响语声y(t)的信号模型如公式(3)表示:
指标。估计结果越准确,ρ就越接近1。
y(t) = s(t) ∗ h(t) + n(t), (3) 对于 n 个样本,皮尔森相关系数 ρ 的公式可
表示为
其中,s(t)表示纯净语声信号,h(t)表示RIR,n(t)表
n
示噪声信号,∗表示卷积操作。 ∑ (T 60,i − T 60 )(T 60,i − T 60 )
b
b
为了提高模型在噪声混响环境中的鲁棒性,本 i=1
ρ = v v , (6)
文在训练时考虑了 ACE 挑战赛中的 3 种加性噪声。 u n 2 u n 2
u∑
u∑
b
b
信噪比从 0 dB、10 dB 和 20 dB 中随机选取,根据 t (T 60,i − T 60 ) t (T 60,i − T 60 )
i=1 i=1
信噪比将噪声按不同比例加入混响语声中。语声
被切分为每句 4 s,采样率为 16 kHz。分别使用 3 种 其中,T 60 表示估计的混响时间的平均值,T 60 表示
b
RIR模拟方法构建的3 个RIR数据库以及真实 RIR 混响时间真实值的平均值。
数据库进行混响语声训练集模拟。每个语声训练集
3 实验与结果讨论
4
总共包含3 × 10 句语声,总时长约为33 h。
2.3 混响时间盲估计模型 3.1 声学实验设置
本文测试使用不同训练集训练的混响时间盲 在模拟训练集时,基于房间LTI系统假设,可以
估计模型的性能,从而间接判断模拟的RIR的质量。 使用纯净语声和 RIR 卷积模拟混响语声。因此,大