
Page 204 - 《应用声学》2023年第4期
P. 204
866 2023 年 7 月
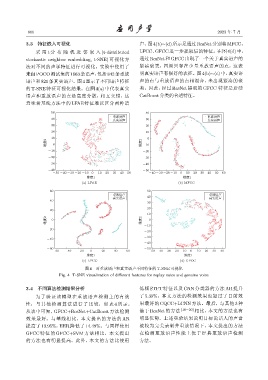
3.3 特征嵌入可视化 声。图4(b)∼(d)所示是通过ResNet分别将MFCC、
采 用 t 分 布 随 机 近 邻 嵌 入 (t-distributed LFCC、GFCC 进一步提取后的特征。在图 4(d) 中,
stochastic neighbor embedding, t-SNE) 可视化方 通过 ResNet 和 GFCC 出现了一个关于真实语声的
法对不同的声学特征进行可视化。实验中使用了 紧凑聚类,四周只存在少量重放语声的点,这表
来自POCO测试集的 1663条语声,包括 842条重放 明真实语声有很好的表征。图 4(b)∼(c) 中,真实语
语声和 821 条真实语声。图 4 显示了不同语声特征 声的点与重放语声的点相混合,未出现紧凑的聚
的 T-SNE 特征可视化结果。在图 4(a) 中代表真实 类。因此,经过 ResNet 提取的 GFCC 特征是后续
语声和重放语声的点是高度分散,相互交错,这 CatBoost分类的合适特征。
意味着基线方法中的 LFAE 特征难以区分两种语
50 40
᧘ஊឦܦ ᧘ஊឦܦ
40 30
ᄾࠄឦܦ ᄾࠄឦܦ
30 20
20 10
10 0
፥ए2 0 ፥ए2 -10
-10 -20
-20 -30
-30 -40
-40 -50
-50 -40 -30 -20 -10 0 10 20 30 40 50 -40-30-20-10 0 10 20 30 40 50 60
፥ए1 ፥ए1
(a) LFAE (b) MFCC
60 50
᧘ஊឦܦ ᧘ஊឦܦ
ᄾࠄឦܦ 40 ᄾࠄឦܦ
40
30
20
20
10
፥ए2 0 ፥ए2 0
-10
-20
-20
-30
-40
-40
-60 -50
-60 -40 -20 0 20 40 60 -50 -40 -30 -20 -10 0 10 20 30 40
፥ए1 ፥ए1
(c) LFCC (d) GFCC
图 4 对重放语声和真实语声不同特征的 T-SNE 可视化
Fig. 4 T-SNE visualization of different features for replay voice and genuine voice
3.4 不同算法检测结果分析 低频 STFT 特征以及 CNN 分类器的方法 AR 提升
为了验证该模型在重放语声检测上的有效 了 5.39%。本文方法的检测效果也超过了目前效
性,与其他检测算法进行了比较,如表 4 所示。 果最好的 CQCC+LCNN 方法。最后,与其他 3 种
从表中可知,GFCC+ResNet+CatBoost 方法检测 基于 ResNet 的方法 [18−20] 相比,本文的方法也有
效果最好。与基线相比,本文提出的方法的 AR 明显优势。上述实验结果说明目标说话人的声音
提高了 13.95%,EER 降低了 14.49%。与同样使用 被较为完美录制并重放情况下,本文提出的方法
GFCC 特征的 GFCC+SVM 方法相比,本文提出 在检测重放语声性能上优于经典重放语声检测
的方法也有明显提高。此外,本文的方法比使用 方法。