
Page 210 - 《应用声学)》2023年第5期
P. 210
1102 2023 年 9 月
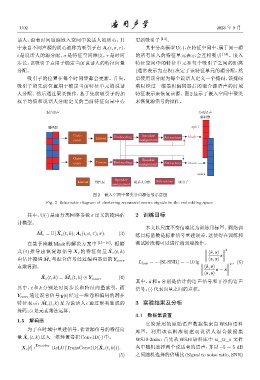
话人,沿着时间追踪嵌入空间中说话人的质心,其 更新吸引子 [13] 。
中来自不同声源的质心被称为吸引子点 A t (i, σ, τ), 其中分离模型U(·),在特征空间中,属于同一源
i 是说话人的源分配,σ 是特征空间维度,τ 是时间 的所有嵌入的特征单元表示会互相吸引 [14] 。嵌入
步长,该吸引子点用于确定当前说话人的特征向量 特征空间中的特征单元和每个吸引子之间的距离
分配。 (通常表示为点积) 决定了该特征单元的源分配,然
吸引子的位置在每个时间步都会更新。首先, 后使用该分配为每个说话人定义一个掩码,该掩码
吸引子的先前位置用于确定当前特征单元的说话 乘以经过一维卷积编码器后的混合源语声的时域
人分配。然后通过聚类操作,基于先前吸引子的加 特征表示来恢复该源。图 2 显示了嵌入空间中聚类
权平均值和说话人分配定义的当前特征向量中心 来恢复源信号的操作。
ຉՌឦܦ Ѭሏឦܦ
ᝍᆊ٨
ᎄᆊ٨ spk1
Gate- Speaker Mask
Linear Embeeding Attractors
conv assignment
Gate- Speaker
conv Linear Embeeding assignment Attractors Mask
spk2
Speaker
Linear ጳভࡏ ឭភ̡Ѭᦡ Attractors ծळߕ
assignment
图 2 嵌入空间中聚类分离源信号示意图
Fig. 2 Schematic diagram of clustering separated source signals in the embedding space
其中,U(·) 是由分离网络参数 σ 定义的掩码估 2 训练目标
计模型。
本文以尺度不变信噪比为训练目标 [8] 。网络训
ˆ
ˆ
M c = U(X c (t, k); A t (i, σ, τ); σ). (3)
练目标函数是标准信号重建误差,这使得在训练和
在基于掩蔽 Mask 的解决方案中 [15−16] ,根据 测试阶段都可以进行端到端操作。
ˆ
式 (4) 推导出恢复源信号 X c 的特征向量 X c (t, k)
2
⟨ˆ s, s⟩
s
ˆ
由估计掩码 M c 与混合信号经过编码器后的 Y conv ⟨s, s⟩
, (6)
L loss = − (SI-SNR) = −10 lg
2
点乘得到。
⟨ˆ s, s⟩
s − ˆ s
⟨s, s⟩
ˆ
ˆ
X c (t, k) = M c (t, k) ⊙ Y conv , (4)
其中, ˆ s 和 s 分别是估计的语声信号和干净的语声
其中,t 和 k 分别是时间步长和特征向量索引,而 信号;⟨·⟩代表向量之间的点积。
Y conv 通过混合信号 y[t] 经过一维卷积编码的潜在
ˆ
特征表示;M c (t, k) 是为说话人 c 通过聚类生成的 3 实验结果及分析
掩码;⊙是元素乘法运算。
3.1 数据集设置
1.5 解码器
实验采用的原始语声数据集来自 WSJ0 语料
为了在时域中重建信号,估计源信号的特征向
库 [8] 。利用该语料库创建双说话人混合数据集
ˆ
量X c (t, k)送入一维转置卷积Conv1D(·)中。
WSJ0-2mix:首先从 WSJ0 语料库中 si_tr_s 文件
Decoder
ˆ
X c [t] ←−−−−− ReLU(TransConv1D(X c (t, k))). 夹中随机选择两个说话者的语声,并以 −5 ∼ 5 dB
(5) 之间随机选择的信噪比(Signal to noise ratio, SNR)