
Page 87 - 《应用声学》2025年第2期
P. 87
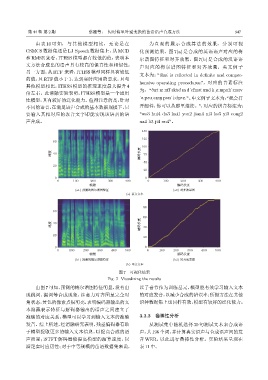
第 44 卷 第 2 期 蔡姗等: 短时傅里叶逆变换的苗语语声合成方法 347
由表 10 可知,与其他模型相比,无论是在 为直观的展示合成算法的效果,分别可视
CSMCS 数据集还是 LJ Speech 数据集上,从 MCD 化预测结果。图 7(a) 是合成的英语语声对应的梅
和 RMSE 来看,ITHSS 模型都有较低的值,表明本 尔谱图特征和对齐效果,图 7(b) 是合成的汉语语
文方法合成出的语声具有较高的保真性和相似性;
声对应的梅尔谱图特征和对齐效果。英文例子
另一方面,从RTF 来看,ITHSS 模型同样具有较低
文本为:“that is reflected in definite and compre-
的值,且 RTF 值小于 1,达到实时应用的要求,且与
hensive operating procedures.”,对应的音素标注
其他模型相比,ITHSS 模型的推理速度最大提升 4
为:“ðæt ɪz ɹɪflˈɛktᵻd ɪn dˈɛfɪnət ænd kˌɑːmpɹɪhˈɛnsɪv
倍左右。此消融实验表明,ITHSS 模型是一个通用
ˈɑːpɚɹˌeɪɾɪŋ pɹəsˈiːdʒɚz.”。中文例子文本为:“我会打
性模型,具有较好的泛化能力。值得注意的是,针对
不同的语言,在满足语声合成的基本数据规模下,只 开邮件,你可以从那里继续。”,对应的拼音标注为:
要输入其相对应的表音文字即能实现该语言的语 “wo3 hui4 da3 kai1 you2 jian4 ni3 ke3 yi3 cong2
声合成。 na4 li3 ji4 xu4”。
150
125
60
100
ጤए 40 ᎄᆊ᫂ए 75
50
20
25
0 0
0 100 200 300 400 0 100 200 300 400
ࣝ ᝍᆊ᫂ए
(a1) ᮕᄊ࠷៨ڏྲढ़ (a2) ࠫᴏ౧ڏ
(a) ᔮవ
80
60
ᎄᆊ᫂ए 60
ጤए 40
40
20
20
0 0
0 100 200 300 400 500 0 100 200 300 400 500
ࣝ ᝍᆊ᫂ए
(b1) ᮕᄊ࠷៨ڏྲढ़ (b2) ࠫᴏ౧ڏ
(b) ˗వ
图 7 可视化结果
Fig. 7 Visualizing the results
由图 7可知,预测的梅尔谱图特征明显,没有出 以子音节作为训练基元,模型能有效学习输入文本
现跳词、漏词等合成现象,注意力对齐图呈完全对 的对应发音,以减少合成的错误率;所提方法在其他
角状态,黄色的像素点很明亮,表明编码器输出的文 语种数据集上也同样有效,模型有较好的泛化能力。
本隐藏表示特征与解码器输出的语声之间建立了
准确的对应关系,模型可以学习到输入文本的准确 3.2.3 鲁棒性分析
发音。综上所述,经消融研究表明,残差编码器有助 从测试集中随机选择 30 句测试文本来合成语
于模型提取更多的输入文本信息,以提高合成的语 声,共196个词,并计算真实语声与合成语声间的发
声质量;iSTFT 解码器能提高模型的演算速度,以 音 WER,以此进行鲁棒性分析。实验结果呈现在
满足实时应用性;对于中等规模的苗语数据集来说, 表 11中。