
Page 125 - 《应用声学》2024年第1期
P. 125
第 43 卷 第 1 期 张寒等: 声纹信号 -图形差分场增强和多头自注意力机制的变压器工作状态辨识方法 121
假设有一离散总点数为 N 的时域信号 y = 上标“T”表示转置。
n
{y 1 , y 2 , · · · , y N }, 可 定 义 时 域 信 号 y 的 图 像 集 为填补K 中的零元素,可定义MDF图像的每
j
G n [14] : 一个通道为
d
}
{
n
G = G n , s = 1, 2, · · · , N − (n − 1) · d , (1) n n n ′ n
d
d,s
L = K + P ⊙ K ,
j j j (6)
式 (1) 中,d 表示为步长,n ∈ (1, N) 表示图像个数,
式(6)中,
G n = y i , i = s, s + d, s + 2d, · · · , s + (n − 1) · d,s
d,s
表示为计算的时间窗口长度。
n 0, s ∈ [1, N − (n − 1) · d] ,
n
则有图像差分集dG : P =
d 1, s ∈ [N − (n − 1) · d, N − (n − 1)] ,
n
dG ={dG n , s = 1, 2, · · · , N − (n − 1) · d}, (2)
d d,s
′ n
⊙ 表示哈达玛积 [15] ,K 是由 K 旋转 180 得到。
n
◦
{ j j
式 (2) 中,dG n = y s+d − y s , y s+2d − y s+d , · · · ,
d,s
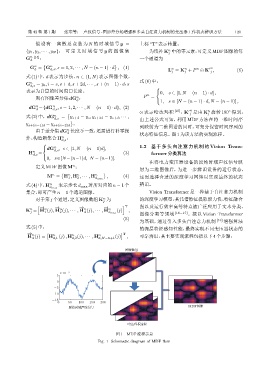
} 由上述公式可知,利用 MDF 方法在将一维时间序
y s+(n−1)d − y s+(n−2)d 。
列映射为二维图谱的同时,可充分保留时间序列的
由于差分集 dG 长度不一致,还需进行补零操
n
d 状态特征信息。图1为该方法的实现流程。
作、构造新集合H n :
d,s
1.2 基于多头自注意力机制的 Vision Trans-
dG n
d,s , s ∈ [1, N − (n − 1)d],
H n = (3) former分类算法
d,s
0, s∈[N −(n−1)d, N − (n−1)].
在将电力变压器设备的原始时域声纹信号映
定义MDF图像M :
n
射为二维图像后,为进一步辨识设备的运行状态,
{
n
n
n
M = H , H , · · · , H n } , (4) 还需选择合适的深度学习网络以实现最终的状态
1 2 d max
式(4)中,H n 表示步长 d max 时所对应的 n − 1 个 辨识。
d max
集合,即可产生n − 1个通道图像。 Vision Transformer 是一种基于自注意力机制
n
对于第j 个通道,定义图像数组K 为 的深度学习模型,其凭借特征提取能力快、特征融合
j
[ −→ −→ − → −→ ] T 强以及运行效率高等特点被广泛应用于文本分类、
n
n
n
n
K = H (j), H (j), · · · , H (j), · · · , H n (j) ,
j 1 2 d d max [16−17]
图像分类等领域 。拟以 Vision Transformer
(5)
为基础,通过引入多头自注意力机制 [18] 增强算法
式(5)中, 的深层特征感知性能,最终实现不同变压器状态的
−→ n [ n n n ] T
H (j) = H d,1 (j) , H d,2 (j), · · · , H d,N−n+1 (j) , 可靠辨识,其主要实现流程包括以下4个步骤:
d
ڏϸጸ
T10 -3
5
0
-5
-10
-15
0 50 100 150 200
Ԕݽ۫ܦጯηՂ MDFڏϸ
ֻထሥሮ
图 1 MDF 流程示意
Fig. 1 Schematic diagram of MDF flow