
Page 10 - 201901
P. 10
6 2019 年 1 月
每个算例计算耗时的均值和方差。以经典深海情 S N = T 1 /T N , (7)
况 (MunkB_Coh_gb) 为例,其环境参数和几何参
T 1 是在单个处理器下的运行时间,T N 是在有 N 个
数见图 5 的计算说明,其均值与标准差结果如图 7
处理器并行系统中的运行时间。
所示。
根据图 7 的计算结果,取 T 1 为 Bellhop 的运行
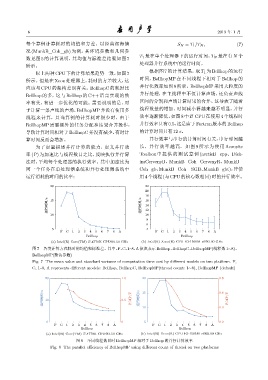
以上两种 CPU下的计算结果趋势一致,如图 7
所示。但是在 Xeon 处理器上,耗时的方差较大,这 时间,BellhopMP 在不同线程下相对于 Bellhop 的
并行化效率如图 8 所示。BellhopMP 采用大粒度的
应该与 CPU 的架构差别有关。BellhopC 的耗时比
Bellhop 的多,这与 Bellhop 的 C++ 语言实现的效 并行处理,在主线程中不仅计算声场,还负责声线
率有关,有进一步优化的可能。需要说明的是,对 区间的分割和声场计算结果的合并。这导致了随着
于计算一条声线的声场,BellhopMP 并没有使用多 线程数量的增加,时间减小得越来越不明显,并行
线程来计算,且当算例的计算耗时很少时,由于 效率逐渐降低,如图 8 中 i7 CPU 在使用 4 个线程时
BellhopMP 需要额外的任务分配和结果合并操作, 并行效率只有0.5,这是由于Fortran版本的Bellhop
导致计算时间相对于BellhopC并没有减少,有时计 的计算时间只有12 s。
算时间反而会增加。 并行效率与串行的计算时间有关,串行时间越
为了定量描述并行计算的能力,定义并行效 长,并行效率越高。如图 9 所示为使用 Acousitc
率 (P) 为加速比与线程数目之比,反映执行并行算 Toolbox 中提供的测试算例 (arcticB_cpp、Dick-
法时,平均每个处理器的执行效率。其中加速比为 insCervenyB、MunkB_Coh_CervenyR、MunkB_
同一个任务在单处理器系统和并行处理器系统中 Coh_gb、MunkB_Coh_ SGB、MunkB_gbt),皆使
运行消耗的时间的比率: 用4个线程(与CPU的核心数相同)时的并行效率。
20 22
20
18
ᤂᛡᫎ/s ᤂᛡᫎ/s 14
16
15
12
10 10
8
6
5 4
F C 1 2 3 4 5 6 7 8 A F C 1 2 3 4 5 6 7 8 A
Bellhop Bellhop
(a) Intel(R) Core(TM) i7-4770K CPU@3.50 GHz (b) Intel(R) Xeon(R) CPU E3-1505M v6@3.00 GHz
图 7 各类计算方式耗时的均值和标准差。其中,F、C、1–8、A 依次表示 Bellhop、BellhopC、BellhopMP(线程数 1∼8)、
BellhopMP(默认参数)
Fig. 7 The mean value and standard variance of computation time cost by different models on two platform. F,
C, 1–8, A represents different models: Bellhop, BellhopC, BellhopMP(thread count: 1∼8), BellhopMP (default)
20 1.0 20 0.8
ᤂᛡᫎ/s 10 0.5 P,MP/F ᤂᛡᫎ/s 15 0.6 P,MP/F
10 0.4
0 0 5 0.2
F C 1 2 3 4 5 6 7 8 A F C 1 2 3 4 5 6 7 8 A
Bellhop Bellhop
(a) Intel(R) Core(TM) i7-4770K CPU@3.50 GHz (b) Intel(R) Xeon(R) CPU E3-1505M v6@3.00 GHz
图 8 不同线程数目时 BellhopMP 相对于 Bellhop 的并行计算效率
Fig. 8 The parallel efficiency of BellhopMP using different count of thread on two platforms