
Page 71 - 《应用声学》2020年第2期
P. 71
第 39 卷 第 2 期 张威等: SE-MCNN-CTC 的中文语音识别声学模型 229
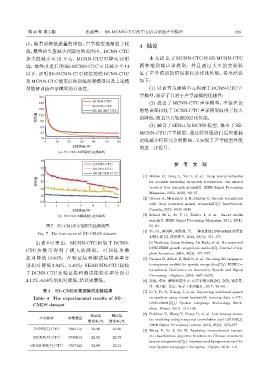
出,随着训练数据量的增加,声学模型逐渐趋于收 4 结论
敛,最终损失值减小到固定的范围内。DCNN-CTC
损失值减小至 19 左右,MCNN-CTC 可降至 16 附 本文提出了 MCNN-CTC 和 SE-MCNN-CTC
近,最终改进后的 SE-MCNN-CTC 可以减小至 14 两种端到端声学模型,并且通过大量的实验验
以下,证明 SE-MCNN-CTC 较传统的 DCNN-CTC 证了声学模型的错误率以及泛化性能,得出结论
及MCNN-CTC能更好地训练深层模型以及上述模 如下:
型能够训练声学模型的有效性。 (1) 以音节为建模单元构建了 DCNN-CTC 声
学模型,验证了其对于声学建模的优越性;
210
DCNN-CTC
180 (2) 提出了 MCNN-CTC 声学模型,不但在识
MCNN-CTC
150
SE-MCNN-CTC 别错误率相较于 DCNN-CTC 声学模型取得了较大
૯ܿϙ 120 的降低,而且具有较强的泛化性能;
90
(3) 融合了 SENet 与 MCNN 模型,提出了 SE-
60
30 MCNN-CTC 声学模型,通过特征通道自适应重标
10 定既减小特征冗余的影响,又实现了声学模型性能
0 10 20 30 40 50 60
ᝫጷ/W 的进一步提升。
(a) ST-CMDSᝫጷ૯ܿԫӑజጳ
40
DCNN-CTC 参 考 文 献
35 MCNN-CTC
SE-MCNN-CTC
30 [1] Hinton G, Deng L, Yu D, et al. Deep neural networks
૯ܿϙ 25 for acoustic modeling in speech recognition: the shared
20 views of four research groups[J]. IEEE Signal Processing
Magazine, 2012, 29(6): 82–97.
15
[2] Graves A, Mohamed A R, Hinton G. Speech recognition
10
0 1 2 3 4 5 6 with deep recurrent neural networks[C]// InterSpeech.
ᝫጷ/W Canada, 2013: 6645–6649.
(b) ST-CMDSॲូ૯ܿԫӑజጳ [3] Seltzer M L, Ju Y C, Tashev I, et al. In-car media
search[J]. IEEE Signal Processing Magazine, 2011, 28(4):
图 7 ST-CMDS 实验损失值曲线图 50–60.
[4] 李云红, 梁思程, 贾凯莉, 等. 一种改进的 DNN-HMM 的语音
Fig. 7 The loss curve of ST-CMDS dataset
识别方法 [J]. 应用声学, 2019, 38(3): 371–377.
由表 4 可得出,MCNN-CTC 相较于 DCNN- Li Yunhong, Liang Sicheng, Jia Kaili, et al. An improved
DNN-HMM speech recognition method[J]. Journal of Ap-
CTC 参 数 量 得 到 了 极 大 的 降 低, 可 训 练 参 数
plied Acoustics, 2019, 38(3): 371–377.
相对降低 13.60%,在验证集和测试集错误率分 [5] Parinia B, Albert Z, Ralf S, et al. On using 2D sequence-
别相对降低 3.94%、3.49%;SE-MCNN-CTC 相较 to-sequence models for speech recognition[C]// IEEE In-
ternational Conference on Acoustics, Speech and Signal
于 DCNN-CTC 在验证集和测试集错误率分别有
Processing. Brighton, 2019: 5671–5675.
4.11%、6.68%的相对降低,错误率最低。 [6] 余栋, 邓力. 解析深度学习: 语音识别实践 [M]. 余凯, 钱彦旻,
译. 第 5 版. 北京: 电子工业出版社, 2017: 78–89.
表 4 ST-CMDS 数据集的实验结果 [7] Li J, Yu D, Huang J, et al. Improving wideband speech
Table 4 The experimental results of ST- recognition using mixed-bandwidth training data in CD-
CMDS dataset DNN-HMM[C]// Spoken Language Technology Work-
shop. Miami, 2013: 131–136.
[8] Peddinti V, Wang Y, Povey D, et al. Low latency acous-
验证集 测试集
声学模型 参数数量 tic modeling using temporal convolution and LSTMS[J].
错误率/% 错误率/%
IEEE Signal Processing Letters, 2018, 25(3): 373–377.
DCNN(7)-CTC 7800110 23.86 23.80 [9] Wang P, Li J, Xu B. Applying connectionist tempo-
MCNN(7)-CTC 6738014 22.92 22.97 ral classification objective function to Chinese mandarin
speech recognition[C]// International Symposium on Chi-
SE-MCNN(7)-CTC 6767342 22.88 22.21 nese Spoken Language Processing. Tianjin, 2016: 1–5.