
Page 149 - 《应用声学》2020年第3期
P. 149
第 39 卷 第 3 期 李鹏等: 基于双向循环神经网络的汉语语音识别 469
行多次调整,当神经元数量到612 时,其错误率最低 由表 2 可看出,Bi-RNN模型对 3 种不同环境下
为53.26%,相比Bi-RNN还是很高,因此并不能简单 的语音库进行训练以及测试。首先通过对表 2 识别
地通过“过拟合” 来解释,说明产生这种现象根本原 错误率中第 1、4、7 三个数据的比较,表明训练和测
因在于 Bi-RNN 与 DNN 结构的差异性。受到协同 试音频类型相同时带有噪声的音频的错误率要比
发音的影响,语音中的各帧之间有着很强的相关性, 无噪声的音频错误率要高,其中白噪声的错误率最
每一个字的发音受到前后几个字的影响。在进行输 高,错误率为 27.16%,这是因为白噪声和咖啡馆噪
入时,DNN 是把相邻的几帧进行拼接,并且其输入 声同属于加性噪声,白噪声属于平稳噪声,咖啡馆噪
窗口是固定的。而 Bi-RNN 在时序问题上能够更好 声属于缓变噪声。白噪声是明确定义的,因为其宽
地体现长时相关性,可以将过去与未来的信息同时 带与均匀连续特点,噪声信号与语音信号重合度很
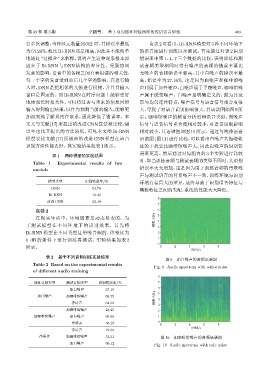
输入得到输出结果,以作为预测当前的输入,能够更 大,导致了对语音识别影响很大,其语谱图如图 9 所
加深刻地了解其内在联系,因此降低了错误率。本 示。咖啡馆噪声的频谱分析虽和语音类似,而噪声
文又与文献[17] 所提出的改进 CNN算法相比较,错 信号与语音信号重合度相对较小,对语音识别影响
误率也比其提出的方法较低,可见本文的 Bi-RNN 相对较小,其语谱图如图 10 所示。通过与纯净语音
模型要比文献 [17] 所提出的改进 CNN 模型在语音 语谱图(图 11) 进行比较,可以看出白噪声共振峰轨
识别方面性能要好。其实验结果如表1所示。 迹的干扰要比咖啡馆噪声大,因此白噪声的识别错
误率更高。然后通过对每组内的 3 个实验进行比较
表 1 两种模型的实验结果
时,即当训练音频与测试音频的类型不同时,其识别
Table 1 Experimental results of two
models 错误率大大增加,这是因为用于训练音频的背景噪
声与测试语音的背景噪声不一致,训练环境与识别
模型类型 识别错误率/% 环境有着巨大的差异,最终导致了识别语音特征与
DNN 54.76
模板特征之间的失配,系统的性能大大降低。
Bi-RNN 19.32
8
改进 CNN 22.19
7
实验2 6
在现实生活中,环境因素是动态易变的。为 ᮠဋ/kHz 5 4
了测试模型在不同环境下的识别效果,首先将 3
Bi-RNN 模型在不同类型且带噪音频的、信噪比为 2
0 dB 的条件下进行训练再测试,实验结果如表 2 1
0
所示。 0 2 4 6 8
ᫎ/s
表 2 基于不同音频训练实验结果
图 9 加白噪声的音频语谱图
Table 2 Based on the experimental results
Fig. 9 Audio spectrum with white noise
of different audio training
8
训练音频类型 测试音频类型 识别错误率/% 7
加白噪声 27.16 6
加白噪声 加咖啡馆噪声 68.75 ᮠဋ/kHz 5 4
净语音 64.33 3
加咖啡馆噪声 24.25 2
加咖啡馆噪声 加白噪声 65.56 1
净语音 56.23 0
0 2 4 6 8
净语音 19.32 ᫎ/s
净语音 加咖啡馆噪声 53.31 图 10 加咖啡馆噪声的音频语谱图
加白噪声 66.12 Fig. 10 Audio spectrum with cafe noise