
Page 36 - 《应用声学》2021年第4期
P. 36
520 2021 年 7 月
0.2
0.2
0
0.2
0 -0.2 ӑ ӑ ӑ ӑ
0 0 ಖюӑ ಖюӑ ಖюӑ ಖюӑ Softmax
-0.2 ດᓕ
-0.2
0 1 2 3 4 0 1 2 3 4 ୕੬ᓙ
Time Time
ԔݽηՂ ۫ԫ૱ ࠇᣃ
ᤊภᣃບ
120
100 Ā
80 120
120 60 100
100 40 80 Conv3 Conv5 Conv7 Лࡍత ᒭཀྵ٪ܦ
80 20 60 120 Conv1 FC
0 40 100 Conv4 Conv6 Conv8 ܸӑ
60 80 Conv2
20
40 60
0
20 40
0 20 8ࡏVGGishᎪፏፇ ᄬಖѬዝ
0 100 200 300 400 0
0 100 200 300 400
128f216f3 ᮠଏᘉ
MelҪဋ៨ͻ˞ᣥКྲढ़ ܙू
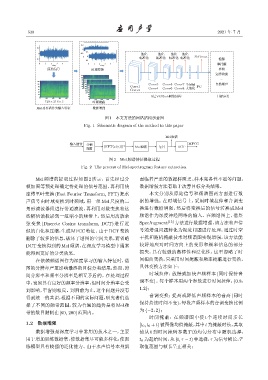
图 1 本文方法的网络结构示意图
Fig. 1 Schematic diagram of the method in this paper
Melᮠ៨
ᣥКηՂ Ѭࣝ 2 MFCC
ҫቔ |FFT(x↼n))| Melฉ lg(S) DCT
图 2 Mel 频谱特征提取过程
Fig. 2 The process of Mel-spectrogram feature extraction
Mel 频谱的提取过程如图 2 所示,首先经过分 面临着严重的数据样匮乏、样本完备性不足等问题,
帧加窗等预处理确定待处理的信号范围,再利用快 数据增强方法有助于改善目标分类结果。
速傅里叶变换(Fast Fourier Transform, FFT)把水 本文分别从原始信号和频谱图两方面进行数
声信号由时域变换到时频域,用一组 Mel 尺度的三 据的增强。在时域信号上,采用时域拉伸和音调变
角形滤波器组进行带通滤波,再利用对数变换将这 换进行数据增强,然后将变换后的信号转换成 Mel
些幅值谱投影到一组缩小的频带上,然后用离散余 频谱作为深度神经网络的输入。在频谱图上,借鉴
弦变换 (Discrete Cosine transform, DCT) 进行近 SpecAugment [15] 方法进行数据增强,该方法将声信
似的白化和压缩,生成MFCC特征。由于DCT变换 号的增强问题转化为视觉问题进行处理,通过时空
删除了较多的信息,破坏了谱图的空间关系,而省略 干扰和随机掩蔽技术对频谱图实现增强,该方法能
DCT变换得到的 Mel频谱,在深度学习模型中通常 较好地应对时间方向上的变形和频率信息的部分
能得到更好的分类效果。 损失,具有较强的鲁棒性和泛化性,这里忽略了时
在依赖频谱图作为深度学习的输入特征时,谱 间扭曲变换,只采用时间掩蔽和频率掩蔽进行变换。
图的分辨率严重影响最终的目标分类结果,然而,时 具体变换方法如下:
间分辨率和频率分辨率是相互矛盾的。在处理过程 时域拉伸:放慢或加快声频样本 (同时保持音
中,宽窗具有良好的频率分辨率,但时间分辨率会受 调不变)。每个样本用两个参数进行时间拉伸:{0.8,
1.2};
到影响,窄窗则相反。到目前为止,这个问题并没有
音调变换:提高或降低声频样本的音高 (同时
得到统一的共识,根据不同的实际问题,研究者们选
保持持续时间不变),每段声频样本的音调变换比例
择了不同的频带范围,较为普遍的趋势是将 Mel 频
为{−2,2};
带的数目限制在[60, 200]范围内。
时间掩蔽:在频谱图中使 t 个连续时间步长
1.2 数据增强 [t 0 , t 0 + t)被图像均值掩蔽,其中t为掩蔽时长,其取
数据增强是深度学习中常用的技术之一,主要 值从 0 到时间掩码参数 T 的均匀分布中随机选择,
用于增加训练数据集,使数据集尽可能多样化,使训 t 0 为起始时间,从[0, τ − t)中选择,τ 为信号帧长,T
练模型具有较强的泛化能力。由于水声信号本身就 取值范围与帧长呈正相关;