
Page 37 - 《应用声学》2021年第4期
P. 37
第 40 卷 第 4 期 刘峰等: 时频谱图和数据增强的水声信号深度学习目标识别方法 521
0.2
0.10 0.10
0.1
0 0 0
-0.1
-0.2 -0.10 -0.10
0 0.5 1.0 1.5 2.0 2.5 3.0 3.5 4.0 4.5 0 0.5 1.0 1.5 2.0 2.5 3.0 3.5 4.0 0 0.5 1.0 1.5 2.0 2.5 3.0 3.5 4.0 4.5
ᫎ/s ᫎ/s ᫎ/s
(a) ԔݽηՂ (b) ۫ઢͩ (c) ᮃូԫ૱
120 120 120
100 100 100
ᮠဋ (bin) 80 ᮠဋ (bin) 80 ᮠဋ (bin) 80
60
60
60
40
40
40
20 20 20
0 0 0
0 100 200 300 400 0 100 200 300 400 0 100 200 300 400
ᫎ (bin) ᫎ (bin) ᫎ (bin)
(d) ԔݽηՂᮠੱ࡙ (e) ઢͩηՂੱ࡙ (f) ᮃូԫӑηՂੱ࡙
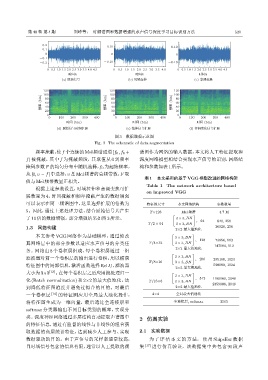
图 3 数据增强示意图
Fig. 3 The schematic of data augmentation
频率掩蔽:使f 个连续的Mel频谱通道[f 0 , f 0 + 谱图作为网络的输入数据,本文将人工特征提取和
f) 被掩蔽,其中 f 为掩蔽频段,其取值从 0 到频率 深度网络模型相结合实现水声信号的识别,网络结
掩码参数F 的均匀分布中随机选择,f 0 为起始频率, 构和参数如表1所示。
从[0, υ − f]中选择,υ 是Mel 频谱的总频带数,F 取
表 1 本文采用的基于 VGG 模型改进的网络构架
值与Mel频带数呈正相关。
Table 1 The network architecture based
根据上述参数设置,时域拉伸和音调变换可扩
on improved VGG
展数量为 4,时间掩蔽和频率掩蔽产生的数据增强
可以表示在同一频谱图中,这里选择扩展的倍数为 特征图尺寸 本文网络结构 参数数量
5。因此,通过上述处理方法,结合原始信号共产生 T×128 Mel 频谱 4.7 M
[ ]
了10倍的数据增强。部分增强结果如图3所示。 3 × 3, BN
, 64 640, 256
T/2 × 64 3 × 3, BN
1.3 网络构建 2×2 最大值池化 36928, 256
本文参考 VGG 网络作为基础模型,通过修改 [ 3 × 3, BN ]
, 128 73856, 512
其网络层中的部分参数以适应水声信号的分类任 T/4×32 3 × 3, BN 147584, 512
2×2 最大值池化
务。网络由 8 个卷积层组成,每个卷积层通过一组
[ ]
滤波器对前一个卷积层的输出进行卷积,用以捕获 3 × 3, BN , 256 295168, 1024
T/8×16 3 × 3, BN
特征图中的局部信息,激活函数选择 ReLU,滤波器 2×2 最大值池化 590080, 1024
大小为3×3 [12] 。在每个卷积层之后应用批处理归一 [ ]
3 × 3, BN
化 (Batch normalization) 和 2×2 的最大值池化,达 T/16×8 3 × 3, BN , 512 1180160, 2048
2359808, 2048
到降低特征图维度并避免过拟合的目的。对最后 2×2 最大值池化
一个卷积层 [16] 的特征图应用全局最大池化操作, 4×4 全局最大值池化
将特征图生成为一维向量,最后通过全连接层和 全连接层, softmax 2565
softmax 分类器输出不同目标类别的概率,实现分
类。深度神经网络通过多层结构自动提取声谱图中 2 仿真实验
的特征信息,通过有监督的线性与非线性的组合获
取数据的高层统计特征,达到减少人工参与、实现 2.1 实验数据
数据驱动的目的。由于声信号的采样率通常较高, 为了评估本文的方法, 使用 ShipsEar 数据
且时域信号包含的信息有限,通常以人工提取的频 集 [17] 进行仿真验证,该数据集中共包含 90 段声