
Page 158 - 《应用声学》2023年第4期
P. 158
820 2023 年 7 月
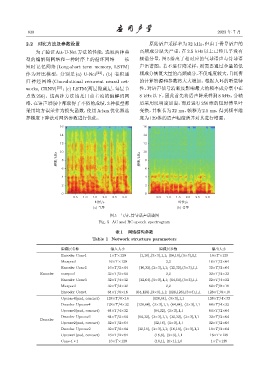
2.2 对比方法及参数设置 原始语声采样率为 32 kHz,但由于骨导语声的
为了验证 Att-U-Net 方法的性能,选取两种典 高频成分缺失严重,在 2.5 kHz 以上已经几乎没有
型的编解码网络和一种时序上的循环网络 ——长 频谱分量,图 5 给出了相对应的气导语声与骨导语
短时记忆网络 (Long-short term memory, LSTM) 声语谱图。若不进行降采样,则需要通过少量的低
作为对比模型,分别是 (a) U-Net [22] ;(b) 卷积递 频成分恢复大量的高频成分,不仅难度较大,且耗费
归神经网络 (Convolutional recurrent neural net- 的计算资源和参数将大大增加。根据人耳的听觉特
works, CRNN) [35] ;(c) LSTM(两层隐藏层,每层节 性,对语声信号清晰度影响最大的频率成分集中在
点数 256)。这两种方法均是目前主流的编解码网 8 kHz 以下,因此首先将语声降采样到 8 kHz,分帧
络,在语声增强中都取得了不俗的成绩,3 种模型都 后采用汉明窗加窗,而后进行 256 维的短时傅里叶
采用均方误差作为损失函数,使用 Adam 优化器选 变换,其帧长为 32 ms,帧移为 2.5 ms,得到频率维
择梯度下降法对网络参数进行优化。 度为129维的语声幅度谱并对其进行增强。
16 16
14 14
12 12
10 10
ᮠဋ/kHz 8 ᮠဋ/kHz 8
6 6
4 4
2 2
0 0
0.5 1.0 1.5 2.0 2.5 3.0 0.5 1.0 1.5 2.0 2.5 3.0
᫂/s ᫂/s
(a) ඡ (b) ᰤ
图 5 气导、骨导语声语谱图
Fig. 5 AC and BC speech spectrogram
表 1 网络结构参数
Table 1 Network structure parameters
隐藏层名称 输入大小 隐藏层参数 输出大小
Encoder Conv1 1×T×129 (1,16),(3×3),1,1; (16,16),(3×3),1,1 16×T×129
Maxpool 16×T×129 2,2 16×T/2×64
Encoder Conv2 16×T/2×64 (16,32),(3×3),1,1; (32,32),(3×3),1,1 32×T/2×64
Encoder maxpool 32×T/2×64 2,2 32×T/4×32
Encoder Conv3 32×T/4×32 (32,64),(3×3),1,1; (64,64),(3×3),1,1 32×T/4×32
Maxpool 32×T/4×32 2,2 64×T/8×16
Encoder Conv4 64×T/8×16 (64,128),(3×3),1,1; (128,128),(3×3),1,1 128×T/8×16
Upconv4(pad, concact) 128×T/8×16 (128,64), (3×3),1,1 128×T/4×32
Decoder Upconv4 128×T/4×32 (128,64), (3×3),1,1; (64,64), (3×3),1,1 64×T/4×32
Upconv3(pad, concact) 64×T/4×32 (64,32), (3×3),1,1 64×T/2×64
Decoder Upconv3 64×T/2×64 (64,32), (3×3),1,1; (32,32), (3×3),1,1 32×T/2×64
Decoder
Upconv2(pad, concact) 32×T/2×64 (32,16), (3×3),1,1 32×T/2×64
Decoder Upconv2 32×T/2×64 (32,16), (3×3),1,1; (16,16), (3×3),1,1 16×T/2×64
Upconv1(pad, concact) 16×T/2×64 (16,8), (3×3),1,1 16×T×129
Conv-1 ∗ 1 16×T×129 (16,1), (1×1),1,0 1×T×129