
Page 69 - 《应用声学》2024年第6期
P. 69
第 43 卷 第 6 期 苌文涵等: 结合改进 DRSE-GCNN 的电力调度语声识别模型 1245
除噪声和冗余信息,提取有效特征。但 ReLU 强制 深度可分离卷积减少了卷积运算中的参数,提
的稀疏处理使一些参数无法激活,出现神经元坏死, 高了计算效率,已成功应用于图像分类任务 [27] 。其
残差结构在训练过程中网络层数较多时训练误差 结构如图4所示。
较大。
नݽ ॆʷӑ-Swish-Ԅሥࡏ
ᣥКឦ៨ڏ ॆʷӑ-Swish-Ԅሥࡏ ஆ᎖ڱ
ஆ᎖ڱ
Ԅሥࡏ(3,64) ॆʷӑ-Swish-Ԅሥࡏ
ॆʷӑ-Swish-Ԅሥࡏ x
ஈᤉງए൵ࣀஆ᎖
Ꭺፏ(3,/2,64) ஆ᎖ڱ ፐࠫϙ-Лࡍࣱکӑ
ஈᤉງए൵ࣀஆ᎖
Ꭺፏ(3,/2,128) Лᤌଌࡏ↼M/c↽
ஈᤉງए൵ࣀஆ᎖ ॆʷӑ-Swish
Ꭺፏ(3,/2,128)
Лᤌଌࡏ↼M/c↽
ʷ፥ງएԻѬሏԄሥ
ॆʷӑ-Swish-ጳভࡏ
256 -ᬤܿำ a
᫃ጳভӭЋ ᄱ˲ Sigmoid
ஈᤉᄊ᫃ԄሥᇸፃᎪፏ ҒᯠᇸፃᎪፏ ஆ᎖ڱ
ᣄϙ
τ
ᬤܿำ
Лᤌଌࡏ-SoftMax
ර֗
y
CTC૯ܿѦ
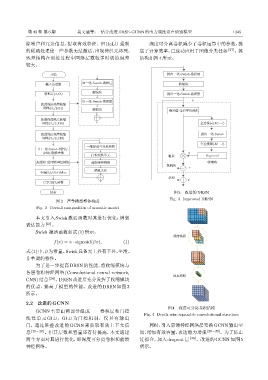
ፇౌ 图 3 改进的 DRSN
Fig. 3 Improved DRSN
图 2 声学模型整体构成
Fig. 2 Overall composition of acoustic model
本文引入 Swish 激活函数对其进行优化,增强
表达能力 [23] 。
Swish 激活函数如式(1)所示:
ງएԄሥ
f(x) = x · sigmoid(βx), (1)
式(1)中,β 为常量。Swish具备无上界有下界、平滑、
非单调的特性。
为了进一步提高 DRSN 的性能,将收缩模块与
各层卷积神经网络 (Convolutional neural network,
ᤪགԄሥ
CNN)结合 [24] 。DRSN改进后充分发挥了收缩模块
的优点,提高了模型的性能。改进的 DRSN 如图 3
所示。
2.2 改进的GCNN
图 4 深度可分离卷积结构
GCNN 主要由两部分组成 ——卷积层和门控
Fig. 4 Depth wise separable convolutional structure
线性单元 GLU,GLU 为门控机制,仅具有输出
门,通过堆叠改进的 GCNN 来获取有效上下文信 同时,引入前馈神经网络层变换GCNN输出空
息 [25−26] 。但其层数和容量还有待提高,本文通过 间,增加有效容量,表达能力增强 [28−29] 。为了防止
两个方面对其进行优化,即深度可分离卷积和前馈 过拟合,加入 dropout 层 [30] 。改进的 GCNN 如图 5
神经网络。 所示。