
Page 71 - 《应用声学》2024年第6期
P. 71
第 43 卷 第 6 期 苌文涵等: 结合改进 DRSE-GCNN 的电力调度语声识别模型 1247
量为定量,多层 GCNN导致后面网络有效信息越来 语谱图相关噪声和冗余信息的阈值,通过阈值消除
越少。 噪声和冗余信息,可以得到有效的特征,且特征更
具有代表性。另外,前馈神经网络层的引入增加了
5.5
GCNN 的有效容量,使得模型提取的上下文信息更
5.0
តᬷ 加有效,识别效果较好。
4.5
ߚᩲឨဋ/% 4.0 ᝫጷᬷ 16.0
3.5
14.0
DRSN-GCNN
3.0
2.5 12.0 ஈᤉDRSN-GCNN
10.0
2.0 ߚᩲឨဋ/% 8.0
6 7 8 9 10 11 12 13 14 DRSN-ஈᤉGCNN
GCNNࡏ 6.0
4.0 వவข
2.0
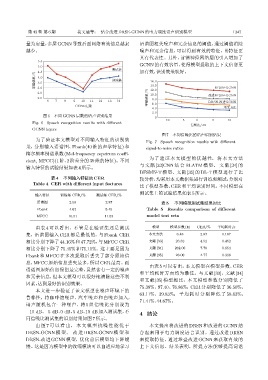
图 6 不同 GCNN 层数的语声识别结果 0
-10 -5 0 5 10
Fig. 6 Speech recognition results with different
η٪උ/dB
GCNN layers
图 7 不同信噪比的语声识别结果
为了验证本文模型对不同输入特征的识别效
Fig. 7 Speech recognition results with different
果,分别输入语谱图、Fbank(40 维的声学特征) 和 signal-to-noise ratios
梅尔频率倒谱系数(Mel-frequency cepstrum coeffi-
为了验证本文模型的优越性,将本文方法
cient, MFCC)(1阶、2 阶差分的 39 维的特征)。不同
与文献 [33]CNN 结合 BLATM 模型、 文献 [34] 的
输入特征的试验结果如表4所示。
DFSMN-T 模型、文献 [35] 的 DL-T 模型进行了比
表 4 不同输入特征的 CER 较分析,均采用本文数据集进行训练和测试,分别对
Table 4 CER with different input features
比了模型参数、CER 和平均识别时间。不同模型在
测试集上的试验结果如表5所示。
输入特征 训练集 CER/% 测试集 CER/%
语谱图 2.58 2.87 表 5 不同模型测试集结果对比
Fbank 4.62 5.49 Table 5 Results comparison of different
MFCC 10.51 11.53 model test sets
由表 4 可以看出,不管是在验证集还是测试 模型 模型参数/M CER/% 平均耗时/s
集,语谱图输入 CER 都是最低的,与 Fbank CER 本文方法 6.48 2.87 0.187
相比分别下降了 44.16%和 47.72%,与MFCC CER 文献 [33] 26.32 4.52 0.452
相比分别下降了 75.45% 和 75.11%。这主要是因为 文献 [34] 262.00 7.78 0.654
Fbank 和 MFCC 在多次提取后丢失了部分原始信 文献 [35] 28.00 4.77 0.338
息,MFCC 原始信息丢失最多,所以 CER 最高。而
由表 5 可以看出,本文模型在模型参数、CER
语谱图原始信息保留最完整,虽然含有一定的噪声
和平均耗时方面均为最佳。与文献 [33]、文献 [34]
和冗余信息,但本文模型可以很好地清除这些不利
和文献 [35] 模型相比,本文模型参数分别降低了
因素,达到最好的识别效果。
75.38%、97.40、76.86%;CER 分别降低了 36.50%、
本文进一步验证了该文模型在噪声环境下的
63.11%、39.83%;平均耗时分别降低了 58.63%、
鲁棒性,将咖啡馆噪声、汽车噪声和白噪声加入,
71.41%、44.67%。
语声随机包含一种噪声,将 5 组信噪比分别设为
−10 dB、−5 dB、0 dB、5 dB、10 dB 加入测试集,不 4 结论
同信噪比测试集的识别结果如图7所示。
由图 7 可以看出, 本文模型抗噪性能优于 本文提出将改进的 DRSN 和改进的 GCNN 结
DRSN-GCNN 模 型、 改 进 DRSN-GCNN 模 型 和 合起来用于电力调度语言识别。通过改进 DRSN
DRSN-改进 GCNN 模型,优化前后模型均下降缓 来提取特征,通过堆叠改进 GCNN 来获取有效的
慢。这是因为模型中的收缩模块可以自适应地学习 上下文信息。结果表明,所提方法能够提高词谱