
Page 56 - 《应用声学》2025年第3期
P. 56
590 2025 年 5 月
t
u
p Conv(64) Residual Block Residual Block Residual Block Residual Block Residual Group1(128) Residual Group2(256) Residual Group3(512) GAP FC(512) Softmax Output
n
I
Conv Conv
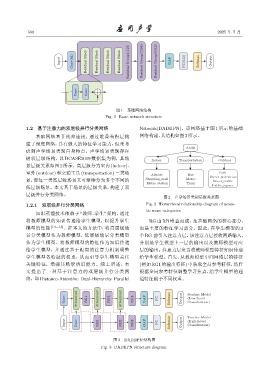
图 1 基础网络结构
Fig. 1 Basic network structure
1.2 基于注意力的双层级并行分类网络 Network(DADHPN)。该网络基于图 1 所示的基础
基础网络基于残差连接,通过堆叠卷积层构 网络构建,其结构如图3所示。
建了深度网络,具有强大的特征学习能力,但未考
Audio
虑到声学场景类别自身特点。声学场景类别存在
树状层级结构,以 DCASE2019 数据集为例,其场
Indoor Transportation Outdoor
景层级关系如图 2 所示。高层级分为室内 (indoor)、
室外 (outdoor) 和交通工具 (transportation)三类场 Airport Bus Park
Street_pedestrian
景,而每一类高层级场景又可继续分为多个不同的 Shopping_mall Metro Street_traffic
Metro_station Tram
低层级场景。本文基于场景的层级关系,构建了双 Public_square
层级并行分类网络。
图 2 声学场景类别层级关系图
1.2.1 双层级并行分类网络 Fig. 2 Hierarchical relationship diagram of acous-
tic scene categories
知识蒸馏技术依赖于 “教师 -学生” 架构,通过
将教师模型的知识传递给学生模型,以提升学生 RG 由 RB 堆叠而成,是基础网络的核心部分,
模型的性能 [14−15] 。在本文的方法中,将高层级场 也是主要的特征学习部分。因此,在学生模型的 3
景分类模型作为教师模型,低层级场景分类模型 个RG 前引入注意力层。该注意力层接收两路输入,
作为学生模型。将教师模型的特征作为知识传递 分别是学生模型上一层的输出以及教师模型对应
给学生模型,并通过基于距离的注意力机制调整 层的输出。注意力层负责将教师模型特征知识传递
学生模型各特征的权重,从而引导学生模型关注 给学生模型。首先,从教师模型中间网络层的特征
关键特征,增强其场景辨识能力。综上所述,本 (例如 RG1 的输出特征) 中获取全局参考特征,然后
文提出了一种基于注意力的双层级并行分类网 根据全局参考特征调整学习焦点,给学生模型的通
络,即 Distance-Attentive Dual-Hierarchy Parallel 道特征赋予不同权重。
Attention1 Attention2 Attention3 FC Softmax Output Student Model
Conv RG1 RG2 RG3 GAP Classification)
(Low-Level
Input Conv RG1 RG2 RG3 GAP FC Softmax Output Teacher Model
(High-Level
Classification)
图 3 DADHPN 结构图
Fig. 3 DADHPN structure diagram