
Page 125 - 应用声学2019年第2期
P. 125
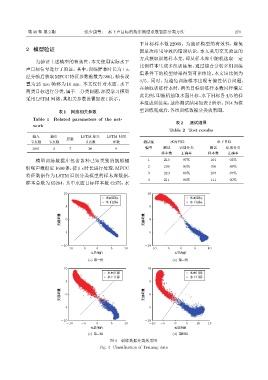
第 38 卷 第 2 期 张少康等: 水下声目标的梅尔倒谱系数智能分类方法 271
下目标样本数 22909。为验证模型的有效性,避免
2 模型验证 因单次结果导致的错误结论,本文采用交叉验证的
方式获取训练样本集,即从样本库中随机选取一定
为验证上述模型的有效性,本文使用实际水下
比例样本生成多组训练集,通过综合分析多组训练
声目标信号进行了验证。其中,训练样本时长为1 s,
集条件下的模型结果得到可靠结论,本文该比例为
经分帧后获取MFCC特征参数维数为3861,帧长设
4/5。同时,为避免训练样本出现有偏性估计问题,
置为 25 ms,帧移为 10 ms。本文仅针对水面、水下
在抽取训练样本时,两类目标训练样本数同样满足
两类目标进行分类,属于二分类问题,深度学习模型
此比例,即随机抽取水面目标、水下目标各 4/5的样
采用LSTM 网络,其相关参数设置如表1所示。
本组成训练集,最终测试结果如表2所示。图4为模
表 1 网络相关参数 型训练完成后,各组训练数据分类效果图。
Table 1 Related parameters of the net-
表 2 测试结果
work
Table 2 Test results
输入 输出 LSTM 单元 LSTM 时间
层数
节点数 节点数 节点数 步数 测试集 水面目标 水下目标
3861 2 7 30 9 编号 测试 识别分类 测试 识别分类
样本数 正确率 样本数 正确率
模型训练数据库包含各种已知类别的舰船辐 1 213 97% 101 93%
射噪声数据近1600条,按1 s 时长进行处理,MFCC 2 209 90% 106 89%
3 210 86% 107 87%
特征数据作为 LSTM 识别分类模型的样本库数据,
4 211 90% 111 90%
样本总数为 65284,其中水面目标样本数 42375,水
10 10
ඵ᭧ᄬಖ ඵ᭧ᄬಖ
ඵʾᄬಖ ඵʾᄬಖ
5 5
ϙጩ᧚ 0 ϙጩ᧚ 0
-5 -5
-10 -10
-10 -5 0 5 10 -10 -5 0 5 10
᧚ጩϙ ᧚ጩϙ
(a) ኄʷጸ (b) ኄ̄ጸ
10 10
ඵ᭧ᄬಖ ඵ᭧ᄬಖ
ඵʾᄬಖ ඵʾᄬಖ
5 5
ϙጩ᧚ 0 ϙጩ᧚ 0
-5 -5
-10 -10
-10 -5 0 5 10 -10 -5 0 5 10 15
᧚ጩϙ ᧚ጩϙ
(c) ኄʼጸ (d) ኄپጸ
图 4 训练数据分类效果图
Fig. 4 Classification of Training data