
Page 131 - 应用声学2019年第4期
P. 131
第 38 卷 第 4 期 曾赛等: 水下目标多模态深度学习分类识别研究 591
ฉ٨ ྲढ़ڏ
Лᤌଌࡏ
(គѿ)
ᣥКڏϸ Ԅሥࡏ1 ʾ᧔ನࡏ1 Ԅሥࡏ2 ʾ᧔ನࡏ2
C 1 S 2 C 3 S 4
图 1 典型的 CNN 网络结构示意图
Fig. 1 The structure of CNN
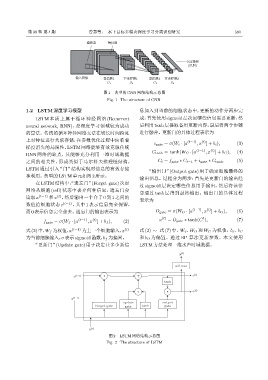
1.2 LSTM深度学习模型 息加入到当前的细胞状态中,更新的动作分两步完
LSTM 本质上属于循环神经网络 (Recurrent 成:首先使用 sigmoid 层决定哪些信息需要更新,然
neural network, RNN),是深度学习领域较为成功 后利用 tanh层提取备用更新内容,最后将两个步骤
的算法。传统的循环神经网络无法在较长时间跨度 进行融合。更新门的具体过程表示为
上对特征进行关联存储,在参数优化过程中面临着
⟨t⟩
i gate = σ(W i · [a ⟨t−1⟩ , x ] + b i ), (3)
梯度消失的局限性,LSTM 网络能够有效克服传统
C tanh = tanh(W C · [a ⟨t−1⟩ , x ] + b C ), (4)
⟨t⟩
RNN 网络的缺点,其能够充分利用一维时域数据
之间的相关性,形成类似于马尔科夫推理链结构。 C t = f gate ∗ C t−1 + i gate ∗ C tanh . (5)
LSTM 通过引入“门”结构实现对信息的有效存储
“输出门”(Output gate) 用于确定细胞最终的
和利用。典型的LSTM单元如图2所示。
输出信息。过程分为两步:首先是更新门的输出经
在 LSTM 结构中,“遗忘门”(Forget gate) 决定
过 sigmoid 层决定哪些信息用于输出,然后将该信
网络从细胞 (cell) 状态中丢弃何种信息,遗忘门会
息通过 tanh 层得到最终输出。输出门的具体过程
读取 a ⟨t−1⟩ 和 x ,然后输出一个介于 0 到 1 之间的
⟨t⟩
表示为
数值给细胞状态 c ⟨t−1⟩ ,其中 1 表示信息完全保留,
而0表示信息完全舍去。遗忘门的输出表示为 O gate = σ(W O · [a ⟨t−1⟩ , x ] + b O ), (6)
⟨t⟩
t
⟨t⟩
f gate = σ(W f · [a ⟨t−1⟩ , x ] + b f ), (2) a ⟨t⟩ = O gate ∗ tanh(C ), (7)
式(2)中,W f 为权值,a ⟨t−1⟩ 为上一个细胞输入,x ⟨t⟩ 式 (3) ∼ 式 (7) 中,W i 、W O 和 W C 为权值,b i 、b C
为当前细胞输入,σ 表示sigmoid函数,b f 为偏置。 和 b O 为偏置。通过 BP 算法更新参数。本文使用
“更新门”(Update gate) 用于决定让多少新信 LSTM方法处理一维水声时域数据。
y <t>
softmax
c <t֓> * ॷ c <t>
tanh
a <t>
* *
a <t֓>
update output
Forget gate gate tanh gate
x <t>
图 2 LSTM 网络结构示意图
Fig. 2 The structure of LSTM