
Page 35 - 《应用声学》2023年第1期
P. 35
第 42 卷 第 1 期 万伊等: 基于 Transformer 编码器的合成语声检测系统 31
达到了最佳性能。由于合成语声检测是为了判断输 间的个数,注意头数目过少,则从特征中学习到信息
入语声是自然语声还是合成语声,更关注输入特征 不足,而过多则可能会学习到与合成语声检测无关
的内部相关性与长期依赖性,而非抽象的语义信息, 的干扰信息。
因此浅层的编码器对合成语声检测更加有效。而在
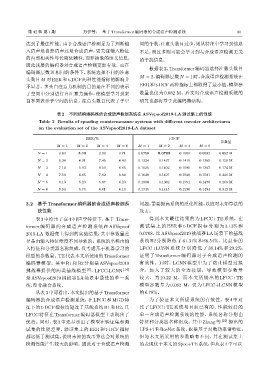
根据表 2,Transformer 编码器选择注意头数目
编码器层数 N 相同的条件下,系统选择不同的注意
M = 2、编码器层数N = 1时,合成语声检测系统在
头数目M 对EER和t-DCF两种性能指标的影响并
EER和t-DCF两种指标上都取得了最小值,模型参
不显著。多头自注意力机制的目的是在不同的表示
子空间中分别进行自注意力操作,使模型学习到来 数量也仅为 0.082 M。后文对合成语声检测系统的
自不同表示子空间的信息。注意头数目代表了子空 研究也都将基于此编码器结构。
表 2 不同结构编码器的合成语声检测系统在 ASVspoof2019-LA 测试集上的性能
Table 2 Results of spoofing countermeasure systems with different encoder architectures
on the evaluation set of the ASVspoof2019-LA dataset
EER/% t-DCF
参数量
M = 1 M = 2 M = 4 M = 6 M = 1 M = 2 M = 4 M = 6
N = 1 3.64 3.13 3.90 3.71 0.0750 0.0708 0.1009 0.0992 0.082 M
N = 2 5.34 6.91 7.45 6.40 0.1324 0.1437 0.1415 0.1369 0.128 M
N = 3 7.14 5.93 8.50 6.65 0.1525 0.1402 0.1595 0.1367 0.174 M
N = 4 7.56 6.65 7.62 8.89 0.1649 0.1497 0.1548 0.1591 0.220 M
N = 5 8.13 5.23 5.87 6.23 0.1800 0.1362 0.1551 0.1478 0.266 M
N = 6 9.94 5.70 6.81 6.10 0.1735 0.1445 0.1596 0.1494 0.312 M
3.2 基于Transformer编码器的合成语声检测系 问题,需要提高系统的泛化性能,以应对未知算法的
统性能 攻击。
表 3 中给出了在不同声学特征下,基于 Trans- 得到本文最佳结果的为 LFCC+TE 系统,在
former 编码器的合成语声检测系统在 ASVspoof 测 试 集 上 的 EER 和 t-DCF 指 标 分 别 为 3.13% 和
2019-LA 数据集上得到的实验结果,其中参数量差 0.0708,比 ASVspoof2019 挑战赛 LA 场景下的基线
异是由输入特征维度不同导致的。系统的名称由输 系统 B2 分别降低了 61.31% 和 66.54%,比最佳的
入特征和分类器名称组成,仅考虑基于机器学习的 LFCC+LCNN 系 统 分 别 降 低 了 38.14% 和 29.2%,
模型的参数量。TE代表本文所使用的Transformer 证明了 Transformer 编码器对于合成语声检测的
编码器模型。其中 B1 和 B2 分别是 ASVspoof2019 有效性。同时,LCNN 模型中为了防止模型过拟
挑战赛提供的两类基线模型 [8] ,LFCC-LCNN [14] 合,加入了较大的全连接层,导致模型参数量
是 ASVspoof2019 挑战赛 LA 场景中最佳的单一系 较大,为 10.22 M,而本文所提出的 LFCC+TE
统,即非融合系统。 模型参数量为 0.082 M,仅为 LFCC+LCNN 模型
从表 3中可看出,本文提出的基于 Transformer 的0.78%。
编码器的合成语声检测系统,在 LFCC 和 MGD 特 为了验证本文所提系统的有效性,表 4 中对
征下的 t-DCF 指标均超过了基线系统 B1 和 B2,且 比了 LFCC+TE 系统与目前已有的、性能较好的
LFCC 特征在 Transformer 编码器模型上表现出了 单一合成语声检测系统的性能,系统名称分别由
优势。同时,表 3 中还显示出了模型在验证集和测 特征和分类器名称组成。其中 Zhang 等 [22] 提出的
试集的性能差异,验证集上的 EER 和 t-DCF 指标 LPS+TE-ResNet 系统,也是基于对数功率谱特征,
都远低于测试集,说明未知的攻击算法会对系统的 但与本文所采用的参数略有不同,其在测试集上
检测性能产生较大的影响。因此对于合成语声检测 的表现优于本文的Spec+TE系统,但从表4中可以