
Page 139 - 《应用声学》2023年第2期
P. 139
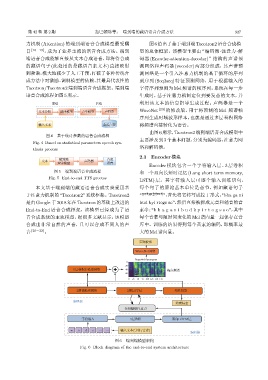
第 42 卷 第 2 期 拉巴顿珠等: 端到端的藏语语音合成方法 327
力机制 (Attention) 的端到端语音合成模型最受瞩 图6给出了基于端到端Tacotron2语音合成模
目 [18−19] ,成为了业界主流的语音合成方法。端到 型的总体框架。该模型主要由“编码器 -注意力 -解
端语音合成能够直接从文本合成语音,即将待合成 码器 (Encoder-attention-decoder)”结构的声谱预
的藏语句子 (此处用的是藏语音素文本) 直接映射 测网络和声码器 (vocoder) 两部分组成,其声谱预
到频谱,极大地减少了人工干预,打破了各种传统合 测网络是一个引入注意力机制的基于循环的序列
成方法中对激励-调制模型的依赖,其最具代表性的 到序列 (Seq2seq) 特征预测网络,用于根据输入的
Tacotron/Tacotron2端到端语音合成框架。端到端 字符序列预测为 Mel 频谱的帧序列,系统在每一步
语音合成流程如图5所示。 生成时,基于注意力机制定位到要发音的文本,并
Ғቫ Ցቫ 利用该文本的信息指导生成过程;声码器是一个
వѬౢ ᮄ॥വی ܦߦവی ܦᆊ٨ WaveNet [23] 的修改版,用于将预测的 Mel 频谱帧
序列生成时域波形样本,也就是通过多层卷积网络
ᣥКవ Ռੇܦᮠ 将频谱直接转化为语音。
由图6所示,Tacotron2端到端语音合成模型中
图 4 基于统计参数的语音合成流程
主要涉及到3 个基本问题,分别为编码器、注意力网
Fig. 4 Based on statistical parameters speech syn-
络和解码器。
thesis process
2.1 Encoder模块
ቫ҂ቫ Ռੇ
వ ܦᆊ٨
ܦߦവی ឦᮃ
Encoder 模块包含一个字符输入层、3 层卷积
图 5 端到端语音合成流程 和一个双向长短时记忆 (Long short term memory,
Fig. 5 End-to-end TTS process
LSTM) 层。其字符输入层可逐个输入训练语句,
本文基于端到端的藏语语音合成实验采用基 每个句子的原始基本单位是音节,例如藏语句子
于注意力机制的 “Tacotron2”系统框架。Tacotron2 “ ”,首先将它转写成拉丁形式:“bha ga ni
是由Google 于2018年在Tacotron的基础上改进的 bud kyi rtogs so”,然后直接被拆成元音和辅音的音
End-to-End 语音合成框架,该模型已经成为了语 素串:“b h a g a n i b u d k y i r t o g s s o”,其中
音合成系统的主流模型,据很多文献显示,该模型 每个音素与随时间变化的Mel谱向量一起保存在音
合成出非常自然的声音,且可以合成不同人的声 库中。训练的结果得到每个音素的编码,即概率最
音 [20−22] 。 大的Mel谱向量。
ܦᮠฉॎ
WaveNetᎪፏ
Target Mel-Spectrogram
0
20
5ࡏԄሥՑܫေᎪፏ 40 ࠷ᮠ៨
60
0 25 50 75 100 125 150 175
2ࡏᮕܫေᎪፏ 2ࡏLSTM ጳভઆॖ
ᝍᆊ٨
ፇౌಖঃ
ͯᎶஐਖฌਓҧ
ߚኀࢦК 3ࡏԄሥ ԥՔLSTMࡏ
w o d e Ā Ā ᣥКవ(ߚኀ/ᮃጉ) ᎄᆊ٨
图 6 端到端模型架构
Fig. 6 Block diagram of the end-to-end system architecture