
Page 140 - 《应用声学》2023年第2期
P. 140
328 2023 年 3 月
2.2 注意力网络 次。客观评价分为训练结果分析和测试结果分析两
Tacotron2 中引入了基于位置敏感的混合注 部分。
意力机制,是对之前注意力机制的扩展,在对齐
3.2.1 训练结果分析
(Alignment) 中加入了位置特征。主要的特点就是
通过实验发现,当模型训练的步数不同时,注
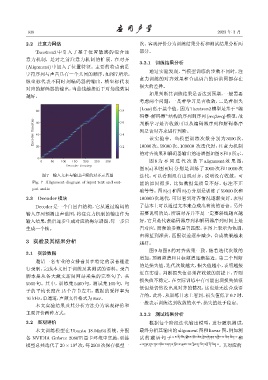
字符序列与声音具有一个共同的顺序,如图 7 所示,
意力训练的对齐效果和合成语音的语谱图都存在
纵坐标代表不同时刻编码器的输出,横坐标代表
很大的差异。
对应的解码器的输出,当曲线越接近于对角线效果
如果判断其训练结果是否达到预期,一般需要
越好。
考虑两个问题:一是看学习是否收敛,二是看损失
(Loss)低于某个值。因为Tacotron2模型是基于“编
80 0.8
码器-解码器”结构的序列到序列(seq2seq)模型,故
Encoder timestep 40 0.4 列是否对齐来进行判断。
0.6
判断学习是否收敛可以从编码器序列和解码器序
60
该实验中,当模型训练次数分别为 3000 次、
10000 次、59000 次、100000 次迭代时,注意力机制
20
0.2
的对齐效果和解码器输出的语谱图如图8和9所示。
0
0 50 100 150 200 250 300 图 8 为 不 同 迭 代 次 数 下 alignment 效 果 图,
Decoder timstep
图 8(a) 和图 8(b) 分别是训练了 3000 次和 10000 次
图 7 输入文本与输出声频的对齐示意图 迭代,可以看到没有出现对齐,说明没有收敛。可
Fig. 7 Alignment diagram of input text and out- 能的原因很多,比如数据集质量不好、标注不正
put audio
确等等。图 8(c) 和图 8(d) 分别是训练了 59000 次和
2.3 Decoder模块 100000 次迭代,可以看到对齐情况逐渐变好,表明
Decoder 是一个自回归结构,它从通过编码的 了基本上可以通过文本来合成出有效的语音。另外
输入序列预测出声谱图,将注意力机制的输出作为 需要说明的是,所谓对齐并不是一定要斜线越直越
输入结果,然后逐步生成对应的梅尔谱图,每一步只 好,它只是代表编码器序列和解码器序列时间上是
生成一个帧。 否对应,而频谱参数是否匹配,在图上表示为色调,
由深蓝到深黄,匹配误差逐步减少,合成效果越来
3 实验及其结果分析 越好。
图 9 与图 8 的对齐效果一致,随着迭代次数的
3.1 实验数据
增加,预测频谱和目标频谱逐渐接近。第二个判断
邀请一名专业的女播音员在特定的录音棚进
的是损失值,迭代次数越大,损失值越小,表明越接
行录制,完成本文用于训练及其测试的语料。录音
近真实谱。判断损失值必须在收敛的前提下,否则
脚本是从各大藏文新闻网站采集的完整句子,共
损失值不稳定。在实际训练中有可能出现损失值很
5500 句。其中,训练集 5400 句,测试集 100 句,句
低但是仍然没出现对齐的情况,这也是无法合成语
子的平均长度在 15 个音节左右,数据的采样率为
音的。此外,从训练日志上看到,损失值低于 0.7 时,
16 kHz,单通道,声频文件格式为wav。
一般表示训练达到收敛的水平,损失值处于稳定。
本文实验结果及其分析方法分为客观评价和
主观评价两种方式。 3.2.2 测试结果分析
3.2 客观评价 根据每个阶段迭代输出模型,进行随机测试,
本文训练模型在 Ubuntu 18.04x64 系统,并配 最终分析其输出的alignment图和linear 图。例如测
备 NVIDIA Geforce 2080Ti 显卡环境中实施,训练 试 的 藏 语 句 子 “ ” 和
模型总共迭代了 20 × 10 次,每2500次保存模型一 “ ”,其对应的
4