
Page 86 - 《应用声学》2023年第2期
P. 86
274 2023 年 3 月
额外的负担,因为知识的转移过程完全在训练阶段 别用I7 8700型号的CPU测量了学生模型和教师模
进行,用于推断的基础模型并未改变。因此,本文算 型处理 6.25 ms 一帧数据所花费的时间,教师模型
法能够无负担地提升学生模型的增强效果。在表 2 单帧执行时间为 3.38 ms,而学生模型则是 2.02 ms,
中可以观察到,除了 MetricGAN 模型外,本文所提 这说明所提师生学习方法在参数量级和延时方面
算法相比其他算法在各项指标上均具有优势地位。 实现了对教师模型的压缩,同时维持了较好的增强
MetricGAN 模型由于其结构是非因果的,并不适 效果。
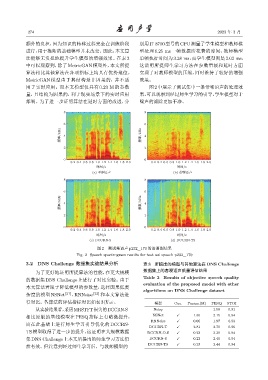
用于实时应用。而本文模型仅具有 0.23 M 的参数 图2中展示了测试集中一条带噪语声的处理效
量,且结构为因果的,利于现实场景下的实时应用 果,可以观察到经过师生学习的引导,学生模型对于
部署。为了进一步证明算法在延时方面的改进,分 噪声的滤除更加干净。
8 8
6 6
ᮠဋ/kHz 4 ᮠဋ/kHz 4
2 2
0 0
0.2 0.4 0.6 0.8 1.0 1.2 1.4 1.6 1.8 2.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 1.6 1.8 2.0
ᫎ/s ᫎ/s
(a) ࣰьឦܦ (b) ࣜ٪ឦܦ
8 8
6 6
ᮠဋ/kHz 4 ᮠဋ/kHz 4
2 2
0 0
0.2 0.4 0.6 0.8 1.0 1.2 1.4 1.6 1.8 2.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 1.6 1.8 2.0
ᫎ/s ᫎ/s
(c) DCCRN-S (d) DCCRN-TS
图 2 测试集语声 p232_170 的语谱图结果
Fig. 2 Speech spectrogram results for test set speech p232_170
3.2 DNS Challenge 数据集实验结果分析 表 3 所提出的模型与其他算法在 DNS Challenge
为了更好地证明所提算法的性能,在更大规模 数据集上的客观语声质量评估结果
的数据集 DNS Challenge 上进行了对比实验。由于 Table 3 Results of objective speech quality
evaluation of the proposed model with other
本文算法着眼于降低模型的参数量,选择因果低复
algorithms on DNS Challenge dataset
杂度的模型 NSNet [21] 、RNNoise [22] 和本文算法进
行对比。各算法的评估指标对比如表3所示。 模型 Cau. Param.(M) PESQ STOI
从实验结果看,采用MRSTFT损失的DCCRN-S Noisy – – 1.58 0.91
相比原版的基线模型在 PESQ 指标上有略微提升, NSNet X 1.30 2.15 0.94
RNNoise X 0.06 1.97 0.93
而在此基础上进行师生学习引导优化的 DCCRN-
DCCRN-T X 2.81 2.70 0.96
TS模型取得了进一步的提升,这证明在大规模数据 DCCRN-O-S X 0.23 2.39 0.94
集DNS Challenge上本文所提出的师生学习方法仍 DCCRN-S X 0.23 2.40 0.94
然有效。但注意到经过师生学习后,与教师模型的 DCCRN-TS X 0.23 2.44 0.94