
Page 144 - 《应用声学)》2023年第5期
P. 144
1036 2023 年 9 月
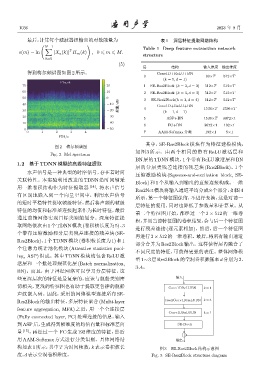
最后,计算每个滤波器组输出的对数能量为 表 1 深层特征提取网络结构
( )
N−1
∑ 2 Table 1 Deep feature extraction network
s(m) = ln |X a (k)| H m (k) , 0 6 m 6 M.
structure
k=0
(5)
层 结构 输入维度 输出维度
得到梅尔频谱图如图2所示。 Conv1D+ReLU+BN
0 80×T 512×T
(k = 5, d = 1)
Fbank
70 20 1 SE-Res2Block (k = 3, d = 2) 512×T 512×T
60 10 2 SE-Res2Block (k = 3, d = 3) 512×T 512×T
50 0 3 SE-Res2Block(k = 3, d = 4) 512×T 512×T
40 -10 ᑟ᧚/dB Conv1D+ReLU+BN
30 -20 4 (k = 1, d = 1) 1536×T 1536×T
20 -30 5 ASP+BN 1536×T 3072×1
10 -40
6 FC+BN 3072×1 192×1
0 -50
0 1 2 3 4 7 AAM-Softmax 分类 192×1 S×1
ᫎ/s
其中,SE-Res2Block 模块作为特征建模模块,
图 2 梅尔频谱图
如图 3 所示,由两个相同的带有 ReLU 激活层和
Fig. 2 Mel spectrum
BN 层的 TDNN 模块、1 个带有 ReLU 激活层和 BN
1.2 基于TDNN模型的高级特征提取
层的分层类残差连接的残差块 (Res2Block)、1 个
水声信号是一种典型的时序信号,存在着时间
压缩激励模块 (Squeeze-and-excitation block, SE-
关联特性。本实验利用改进的 TDNN 沿时间轴采
Block)和 1 个从输入到输出的直接连接构成。一维
用一维卷积结构作为特征提取器 [14] ,将水声信号
Res2Net 模块将输入通道平均分成 8 个部分,如图 4
有区别地嵌入到一个向量空间中,利用水声信号
所示,第一个特征图保留,不进行变换,这是对前一
的短时平稳特性提取帧级特征,然后将声频的帧级
层特征的复用,同时也降低了参数量和计算量。从
特征的均值和标准差连接起来作为长时特征,最后
第二个特征图开始,都经过一个 3 × 512 的一维卷
通过前馈网络实现目标类别的划分。深度特征提
积,并且当前特征图的卷积结果,会与后一个特征图
取网络依次由 1 个 TDNN 模块 (卷积核长度为 5)、3
进行残差连接 (逐元素相加)。然后,后一个特征图
个带有压缩激励和分层类残差连接的残差块 (SE-
再进行 3 × 512的一维卷积。最后,将所有输出通道
Res2Block)、1 个 TDNN 模块 (卷积核长度为 1) 和 1
部分合并为 Res2Block 输出。这样使得层内融合了
个注意力统计池化模块 (Attentive statistics pool-
不同尺度的特征,可获得更强的表征。整体网络模
ing, ASP) 组成。其中 TDNN 模块均包含 ReLU 激
型1∼3层Res2Block的空洞卷积膨胀率d分别为2、
活层和一个批处理规范化层 (Batch normalization,
3、4。
BN)。而且,由于神经网络可以学习分层特征,这
些更深层次的特征是最复杂的,应该与舰船类别密 ᣥК
切相关,更浅的特征图也有助于提取更鲁棒的舰船 Conv1DReLUBN k/
声纹嵌入码。因此,采用的网络模型连接所有 SE-
Res2Block 的输出特征,多层特征聚合 (Multi-layer Res2Conv1DReLUBN k/
feature aggregation, MFA) 之后,用一个全连接层
Conv1DReLUBN k/
(Fully connected layer, FC) 处理连接的信息,输入
到ASP后,生成得到帧维度的均值向量和标准差向 SE-Block
量 [15] ,再经过一个 FC 生成 192 维度的特征,然后
用 AAM-Softmax 方式进行分类识别。具体网络结 ᣥѣ
构如表 1 所示,其中 T 为时间帧数,k 表示卷积核长 图 3 SE-Res2Block 结构示意图
度,d表示空洞卷积维度。 Fig. 3 SE-Res2Block structure diagram