
Page 148 - 《应用声学)》2023年第5期
P. 148
1040 2023 年 9 月
2.3 实验结果对比及分析 个类别中包含了多种不同型号的船只,这些目标的
选择循环神经网络(Recurrent neural network, 类内一致性和类间可分性问题还值得进一步研究,
RNN)模型和深度神经网络(Deep neural networks, 如其他类别中包含了海监船、拖船等多种型号的船
DNN) 模型作为对照实验,来验证本文实验模型的 只;三是由于采集环境受限,本文的数据采集位于近
有效性。表 4 中比较了基于 ShipsEar 数据集各种 岸,噪声干扰较大,难以稳定采集到观测目标的声纹
模型的水下声学信号识别的准确率。根据实验结 信号,这些都会对分类问题造成干扰。本次实验所
果,本文采用的基于注意力机制改进的 TDNN 模型 测数据更接近真实环境下的需求,可在一定程度上
(Fbank-attention-TDNN)的错误率最低,其准确率 对本文所提方法进行验证。
表明有 79.2% 的机会正确识别水下声学信号的类
型。由于全连接神经网络 (Fully connected neural 0.9
network, FCNN) 模型的 FC 的参数最多,模型在训 0.8
练过程中更容易过拟合,因此会提高了模型的错误 0.7
率,使模型在测试过程中准确率最低。虽然传统的 юᆸဋ 0.6
RNN模型和DNN模型利用连接的模型也同样稳定 ᝫጷᬷюᆸဋ
0.5 តᬷюᆸဋ
地收敛了,但效果不及本文实验的模型。原因是
0.4
TDNN 结合了信号的长时关联性,更好地利用了梅
0 10 20 30 40 50
尔谱图前帧和后帧的时间相关性以及频率的结构
ᤖ̽ևర
信息,同时,本文实验的模型也使用了残差连接多尺
图 8 训练和测试准确率对照曲线
度特征聚合,可以接受全局信息的特点使得模型在
Fig. 8 Comparison curve of training and test ac-
训练过程中学习每个网络层的信息,会令模型的错
curacy
误率逐渐下降,当注意力机制被引入模型时,模型的
效果更加稳健。在不牺牲特征信息的情况下,本文
采用的模型相较于传统结果可能会大幅减少参数, 4 ᝫጷᬷ૯ܿ
តᬷ૯ܿ
使其能够产生最好的结果。 3
૯ܿ
表 4 实验结果 (基于 ShipsEar 数据集)
2
Table 4 Experimental results(Based on
ShipsEar dataset) 1
模型 准确率/% 0
0 10 20 30 40 50
Fbank-attention-TDNN 79.2 ᤖ̽ևర
Fbank-TDNN 73.5
图 9 训练和测试损失对照曲线
Fbank-RNN 74.2
Fig. 9 Comparison curve of training and test loss
Fbank-DNN 75.4
Fbank-K-near neighbor 72.5 图 10 为本文方法在测试集识别结果的混淆矩
Fbank-FCNN 71.5
阵,可用来呈现算法性能的可视化效果,每一列代表
采用上述相同的方法对本文构建的数据集进 了预测类别,每一列的总数表示预测为该类别的数
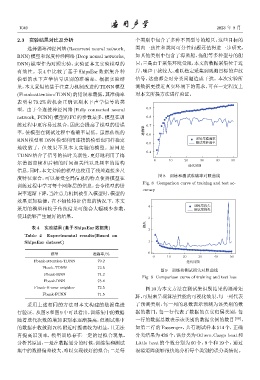
行验证。从图8和图9 中可以看出,训练集中的数据 据的数目;每一行代表了数据的真实归属类别,每
随着迭代次数的增加识别率逐渐提高,但测试集中 一行的数据总数表示该类别的数据实例的数目 [18] 。
的数据在收敛到 70% 附近时振荡较为明显,且无法 如第二行的 Passenger,共有测试样本 514 个,正确
再提高识别率,模型训练存在一定的过拟合现象。 分类结果为426个,误分类为Others、Cargo boat和
分析其原因,一是在数据划分的时候,训练集和测试 Little boat 的个数分别为 60 个、9 个和 19 个,通过
集中的数据偏差较大,难以实现较好的拟合;二是每 混淆矩阵能够很快地分析每个类别的误分类情况。