
Page 200 - 《应用声学)》2023年第5期
P. 200
1092 2023 年 9 月
ҒቫᎪፏവڱ ฌਓҧ҄ᚸՌവڱ ՑቫѬዝവڱ
dB
MFCC
+100
0
−100
2D-CNN
−200 Ꭺፏ ˗ᫎࡏ
−300
−400
0 0.5 1.0 1.5 2.0
Time/s
ଢԩMFCCྲढ़
Original wave dB
6 IMFCC
+300
4
2 ឦܦ +200 2D-CNN SEᤰ᥋ Ցቫ
Amplitude 0 ྲढ़ +100 Ꭺፏ ˗ᫎࡏ ฌਓҧᚸՌ Ѭዝ٨
ଢԩ
−2
0
−4
−6 −100
−8 0 0.5 1.0 1.5 2.0
0 0.5 1.0 1.5 2.0 Time/s
Time ଢԩIMFCCྲढ़
ឦܦηՂ dB
Wavelets
+8
+6
LSTM
+4 ˗ᫎࡏ
Ꭺፏ
+2
+0
0 0.5 1.0 1.5 2.0
Time/s
ଢԩSCNCྲढ़
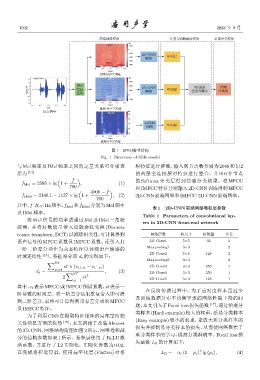
图 1 SER 模型结构
Fig. 1 Structure of SER model
与 Mel 频率及 IMel 频率之间的定量关系可分别表 积特征进行降维,输入到节点数分别为 2048 和 512
示为 [14] 的两层全连接层对特征进行整合,并由 6 个节点
f 的 Softmax 分类层得到情感分类结果。将 MFCC
( )
f Mel = 2595 × lg 1 + , (1)
700 和IMFCC特征分别输入2D-CNN 训练得到MFCC
4000 − f
( )
f IMel = 2146.1 − 1127 × lg 1 + , (2) 2D-CNN前端网络和IMFCC 2D-CNN前端网络。
700
其中,f 表示 Hz 频率,f Mel 和f IMel 分别为 Mel 频率
表 1 2D-CNN 前端网络卷积层参数
及IMel频率。
Table 1 Parameters of convolutional lay-
将语声信号的功率谱通过 Mel 及 IMel 三角滤
ers in 2D-CNN front-end network
波器,并将对数能量带入离散余弦变换 (Discrete
cosine transform, DCT)以消除相关性,可计算得到 网络层数 核尺寸 核数量 步长
语声信号的 MFCC 系数及 IMFCC 系数。还引入其 2D Conv1 5×5 32 2
一阶二阶差分项作为动态特征以体现语声情感的 Maxpooling1 3×3 2
2D Conv2 5×5 128 2
时域连续性 [15] 。特征差分项 d t 的实现如下:
Maxpooling2 3×3 2
∑ ST
st × (c t+st − c t−st ) 2D Conv3 3×3 256 1
d t = st=1 , (3) 2D Conv4 3×3 256 1
∑ ST
2 st 2 2D Conv5 3×3 128 1
st=1
其中,c t 表示MFCC或IMFCC倒谱系数,st表示一
在反向传播过程中,为了应对由样本量过少
阶导数的时间差。将一阶差分结果重复带入即可得
及训练数据分布不均衡导致的网络性能下降的问
到二阶差分,最终可计算得到带有差分项的 MFCC
题,本文引入了Focal loss损失函数 [17] ,通过给难分
及IMFCC特征。
类样本 (Hard example) 较大的权重,给易分类样本
为了利用 CNN 在提取特征矩阵的局部空间相
(Easy example) 较小的权重,来放大难分类样本的
关性信息方面的优势 [16] ,本文搭建了改进 Alexnet
损失并抑制易分类样本的损失,从而使网络聚焦于
的2D-CNN,网络结构简图如图 2 所示,网络卷积部
难分类样本的学习,提高分类准确率。Focal loss 损
分的结构参数如表 1 所示。卷积层使用了 ReLU 激
失函数 L fl 的计算如下:
活函数,并进行了 L2 正则化,正则化参数为 0.02。
γ
在完成卷积运算后,使用扁平化层 (Flatten) 对卷 L fl = −α t (1 − p t ) lg (p t ) , (4)