
Page 23 - 《应用声学》2024年第6期
P. 23
第 43 卷 第 6 期 赵子杰等: 应用原型网络的小样本次声信号分类识别方法 1199
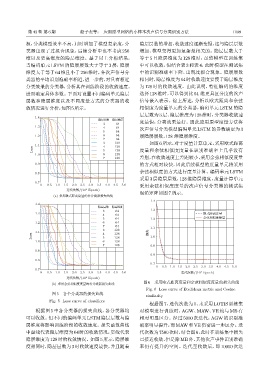
源,分类模型效率不高,同时增加了模型复杂度,分 隐层层数的增加,收敛速度逐渐变慢,这与隐层层数
类器出现了过拟合现象,后续分析中也不考虑 256 增加、模型变得更加复杂是相关的。隐层层数大于
维以及更高维度的隐层维度。基于以上分析结果, 等于 5 且隐层维度为 128 维时,虽然模型在训练集
当编码单元 LSTM 的隐层层数大于等于 3 层,隐层 中可以收敛,但结合表 3 和表 4,此时模型在测试集
维度大于等于 64 维且小于 256 维时,各次声信号分 中的识别准确率下降,出现过拟合现象。隐层层数
类器的平均识别准确率相近,进一步的,对具有相近 相同时,隐层维度为64时收敛速度要慢于隐层维度
分类效果的分类器,分析其在训练阶段的收敛速度, 为 128 时的收敛速度。由此说明,特征编码的维度
进而确定具体参数。下面对设置不同编码单元隐层 选择 128维时,可以得到比 64 维更具区分度的次声
层数和隐层维度以及不同度量方式的分类器的收 信号嵌入表示。综上所述,分析以欧式距离和余弦
敛情况进行分析,如图5所示。 相似度为度量单元的分类器,编码单元 LSTM 的隐
层层数为 3 层、隐层维度为 128 维时,分类器收敛速
1.4
ᬥࡏࡏ ᬥࡏ፥ए
3 64 度最快,分类效果最好。因此应用原型度量方法将
1.3 4 64 次声信号分类模型编码单元 LSTM 的参数确定为 3
5 64
1.2 6 64 层隐层层数,128 维隐层维度。
7 64
3 128 如图6所示,对于度量计算单元,采用欧式距离
1.1 4 128
Loss 5 128 度量和余弦相似度度量在识别准确率上几乎没有
1.0 6 128
7 128 差别,在收敛速度上差距较小,采用余弦相似度度量
0.9 的方式相对较快,因此后续模型的度量单元将采用
余弦相似度的方式进行度量计算。编码单元 LSTM
0.8
采用 3 层隐层层数,128 维隐层维度,度量计算单元
0.7
0 0.5 1.0 1.5 2.0 2.5 3.0 3.5 4.0 4.5 5.0 采用余弦相似度度量的次声信号分类器的测试集
4
ᤖ̽/(10 Epoch)
混淆矩阵如图7所示。
(a) ᧔ၹൗरᡰሏए᧚ᄊՊѬዝ٨૯ܿజጳ
1.4
1.4
ᬥࡏࡏ ᬥࡏ፥ए
3 64 1.3
1.3 ൗरᡰሏए᧚
4 64
5 64 1.2 ऺᄱͫएए᧚
1.2 6 64
7 64 1.1
3 128
1.1 4 128 ૯ܿ
Loss 5 128 1.0
1.0 6 128
7 128 0.9
0.9
0.8
0.8
0.7
0 0.5 1.0 1.5 2.0 2.5 3.0 3.5 4.0 4.5 5.0
0.7
4
0 0.5 1.0 1.5 2.0 2.5 3.0 3.5 4.0 4.5 5.0 ᤖ̽/(10 Epoch)
4
ᤖ̽/(10 Epoch)
图 6 采用欧式距离度量和余弦相似度度量的损失曲线
(b) ᧔ၹऺᄱͫएए᧚ᄊՊѬዝ٨૯ܿజጳ
Fig. 6 Loss curve of Euclidean metric and Cosine
图 5 各个分类器的损失曲线 similarity
Fig. 5 Loss curve of classifiers
根据图 7,迭代次数为 0、未采用 LOTIS 训练集
根据图 5 中各分类器的损失曲线,各分类器均 对模型进行训练时,AGW、MAW、VE 均与 MB 有
可以收敛。但不同的编码单元 LSTM隐层层数与隐 相对明显区分。经过 5000 次迭代,AGW 的识别准
层维度将影响训练阶段的收敛速度。损失函数曲线 确率明显提升,而MAW和VE仍需进一步区分。迭
中虚线代表隐层维度为 64时的收敛情况,实线代表 代次数为7500次时,结合图6,此时在训练集中损失
隐层维度为 128时的收敛情况。如图5 所示,隐层维 已接近收敛,但是除MB外,其他次声事件识别准确
度相同时,隐层层数为 3 时收敛速度最快,并且随着 率仍有提升的空间。迭代至收敛后,即 10000 次迭