
Page 147 - 《应用声学》2025年第2期
P. 147
第 44 卷 第 2 期 王嘉文等: 藏语语声识别声学模型建模单元研究 407
于注意力机制的深度卷积模型。通过实验结果得到 南等省区,在中国境内使用的藏语分为卫藏方言、
具有适用性更高同时识别效果更优秀的建模单元, 康巴方言、安多方言 [25] ,它们的主要差异在于语
从而有效提高藏语语声识别的研究效率。 声方面,尤其是安多方言和卫藏方言之间的差异
较大,难以流利地交流,而康巴方言则介于两者之
1 基于多种建模单元的端到端藏语语声 间 [26] 。藏语三大方言文法相同但又存在极大的发
识别
音差异,有很高的研究价值。藏语语声合成数据集
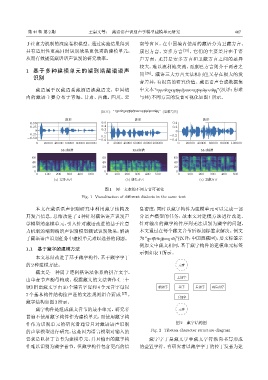
藏语属于汉藏语系藏缅语族藏语支,中国境 中文本 “དཀའ་བའི་ ས་ ་ ོགས་ ི་བཟང་ངན་ ོགས་ཞེས་པ་བཞིན།”(汉译:患难
内的藏语主要分布于青海、甘肃、西藏、四川、云 与共)不同方言的发音可视化如图1所示。
<ჰ໓>:þ ÿ(ᬲˁС)
ฉॎ ฉॎ ฉॎ
0.50 0.6 0.4
0.25 0.4 0.2
0 0.2 0
-0.25 -0.2 0 -0.2
-0.50
-0.4 -0.4
0 20000 40000 60000 80000 100000 0 20000 40000 60000 80000 100000 0 20000 40000 60000 80000 100000
Melᮠ៨ Melᮠ៨ Melᮠ៨
60 60 60
40 40 40
20 20 20
0 0 0
0 100 200 300 400 500 0 100 200 300 400 500 0 100 200 300 400 500
(a) ߷ܳவᝓ (b) कࣅவᝓ (c) Ӽᘩவᝓ
图 1 同一文本的不同方言可视化
Fig. 1 Visualization of different dialects in the same text
本文在藏语语声识别研究中利用藏字结构及 息密度,同时以藏字构件为建模单元可以完成一部
其发音信息,总结改进了 4 种针对藏语语声识别声 分语声模型的任务,故本文对建模方法进行改进。
学模型的建模单元,引入针对藏语改进的基于注意 针对输出的藏字构件序列无法识别为藏字的问题,
力机制的端到端语声识别模型测试识别效果,解决 本文通过在每个藏文音节后添加标签来解决。例文
了藏语语声识别任务中建模单元难以选择的问题。 为“ ང་གོའི་བོད་ ོངས་ ་བའི།”(汉译:中国西藏网),后文标签示
例原文中藏文相同,基于藏字构件的建模单元标签
1.1 基于藏字的建模方法
示例如表1所示。
本文总结改进了基于藏字构件,基于藏字字丁
的2种建模方法。 Ћᮃ
藏文是一种属于逻辑格语法体系的拼音文字,
由单音节声韵母构成。根据藏文的文法著作《三十 ʽҫߚ
颂》指出藏文字由 30 个辅音字母和 4 个元音字母以 Ғҫߚ ۳ߚ Ցҫߚ гՑҫߚ
7 个基本构件结构按严谨的文法规则组合而成 [27] 。
ʾҫߚ
藏字结构如图2所示。
藏字构件是组成藏文音节的最小单元。研究者 Ћᮃ
普遍不使用藏字构件作为建模单元,而使用藏字构
件作为识别单元的研究者通常只对藏语语声识别 图 2 藏字结构图
的声学模型进行研究,这是因为语言模型对输入的 Fig. 2 Tibetan character structure diagram
要求是以拉丁音节为建模单元,并且输出的藏字构 藏字字丁是藏文字中藏文字符纵向书写形成
件难以识别为藏字音节。但藏字构件包含更高的信 的叠置字符。有研究者以藏字字丁的拉丁发音为建