
Page 84 - 《应用声学》2025年第3期
P. 84
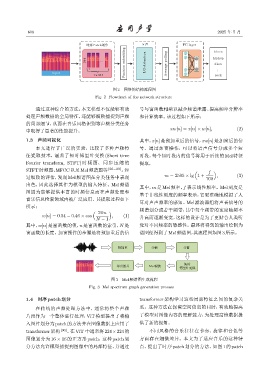
618 2025 年 5 月
ऀPatchѳѬ fN FC layer blues
Position enbedding LG-Attention Average polling . . . . disco
244 ... . . hiphop
1 ...
Input
1f244 rock
图 2 网络的结构流程图
Fig. 2 Flowchart of the network structure
通过这种综合的方法,本文模型不仅能够有效 号与窗函数相乘以减少频谱泄露、提高频率分辨率
处理声频数据的全局特征,还能够细致捕捉到声频 和计算效率。该过程如下所示:
的局部细节,从而在音乐风格识别等声频分类任务
中取得了显著的性能提升。 xw[n] = x[n] × w[n], (2)
1.3 声频可视化 其中,x[n] 是预加重后的信号,xw[n] 是加窗后的信
本文进行了广泛的实验,比较了多种声频特 号。通过加窗操作,可以将语声信号分成多个短
征提取技术,涵盖了短时傅里叶变换 (Short time 时段,每个短时段内的信号将用于后续的 Mel 特征
Fourier transform, STFT) 时频图、 同步压缩的 提取,
STFT时频图、MFCC以及Mel频谱图等 [26−29] 。经
f )
(
过细致的评估,发现 Mel 频谱图在分类任务中表现 m = 2595 × lg 1 + 700 , (3)
出色,因此选择其作为模型的输入特征。Mel 频谱
其中,m 是 Mel 频率,f 表示线性频率。Mel 刻度是
图因为能够提供丰富的时频信息而在声频处理和
基于非线性刻度的频率表示,它更准确地模拟了人
音乐信息检索领域内被广泛应用。其提取过程如下
耳对声声频率的感知。Mel 滤波器组将声音信号的
所示:
频谱划分成若干频带,其中每个频带的宽度随频率
( 2πn )
w[n] = 0.54 − 0.46 × cos , (1) 升高而逐渐变宽,这样的设计是为了更贴合人类听
N − 1
其中,w[n] 是窗函数的值,n 是窗函数的索引,N 是 觉对不同频率的敏感性。最终将得到的输出绘制为
窗函数的长度。加窗操作的步骤是将预加重后的信 谱图便得到了Mel频谱图,其流程图如图3所示。
ᮕҫ᧘ Ѭࣝ Ѭቔ
ᆁ
ѣڏྟ Melฉ
Ϭ᧗Ձԫ૱
图 3 Mel 频谱图生成流程
Fig. 3 Mel spectrum graph generation process
1.4 时序patch划分 transformer 架构学习这些局部特征之间的复杂关
在传统的声频处理方法中,通常将整个声频 系。这种方法在保留空间信息的同时,有效地提高
片段作为一个整体进行处理,ViT 模型提出了将输 了模型对图像内容的理解能力,为处理高维数据提
入图片划分为 patch 的方法并在图像数据上应用了 供了新的视角。
transformer架构 [30] 。在ViT 中通常将224 × 224的 不同风格的音乐往往在节奏、旋律和音色等
图像划分为 16 × 16 的正方形 patch,这种 patch 划 方面存在细微差异。本文为了适应音乐的这种特
分方法允许模型捕捉到图像中的局部特征,并通过 点,提出了时序 patch 划分的方法,如图 1 的 patch