
Page 87 - 《应用声学》2025年第3期
P. 87
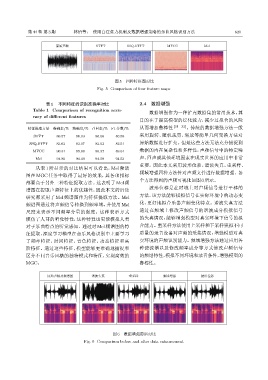
第 44 卷 第 3 期 林怡等: 使用自注意力机制及数据增强策略的乐曲风格识别方法 621
Ԕݽܦᮠ STFT SSQ-STFT MFCC Mel
图 5 四种特征图对比
Fig. 5 Comparison of four feature maps
表 1 不同特征的识别准确率对比 2.4 数据增强
Table 1 Comparison of recognition accu-
数据增强作为一种扩充数据集的常用技术,其
racy of different features
目的在于提高模型的泛化能力,减少过拟合的风险
特征提取方法 准确率/% 精确度/% 召回率/% F1 分数/% 从而增加鲁棒性 [31−32] 。传统的数据增强方法一般
STFT 86.57 86.03 86.06 86.58 采用旋转、随机裁剪、缩放等简单几何变换方法对
SSQ-STFT 83.62 83.07 82.03 82.51 原始数据进行扩充。但是这些方法无法充分捕捉到
MFCC 90.31 89.88 89.37 89.61 数据的内在复杂性和多样性,声频信号中的特定噪
Mel 94.80 94.49 94.58 94.53 声、回声或其他环境因素在现实世界的应用中非常
重要。因此本文采用波形位移、谐波失真、重采样、
从表 1 所显示的对比结果可以看出,Mel 频谱
频域增强四种方法针对声频文件进行数据增强。各
图在 MGC 任务中取得了最好的效果,其各项指标
个方法得到的声频可视化如图6所示。
都要高于另外三种特征提取方法。这表明了 Mel频
谱图在提取声频特征上的优越性,因此本文的后续 波形位移是在时域上对声频信号进行平移的
方法,该方法能够模拟信号在实际环境中的动态变
研究都采用了 Mel 频谱图作为特征提取方法。Mel
频谱图通过将声频信号转换到频率域,并使用 Mel 化,更好地拟合乐器声频变化特点。谐波失真方法
尺度来表示不同频率分量的强度。这种表示方式 通过在频域上修改声频信号的谐波成分模拟信号
模仿了人耳的听觉特性,这种特性也更能模拟人类 的失真情况,能够增强模型对真实环境下信号的拟
对于乐曲特点的听觉感知。通过对 Mel 频谱图的特 合能力。重采样方法使用上采样和下采样模拟不同
征提取,深度学习模型在音乐风格识别中主要学习 质量的录音设备对声频的采集情况,增强模型对真
了频率特征、时间特征、音色特征、动态特征和高 实环境的声频识别能力。频域增强方法通过应用各
阶特征。通过这些特征,模型能够更准确地捕捉和 种滤波器以及修改频率成分等方式修改声频信号
区分不同音乐风格的独特模式和特征,实现高效的 的频谱特性,模拟不同环境和录音条件,增强模型的
MGC。 鲁棒性。
Ԕݽܦᮠԣᮠ៨ڏ ៈฉܿᄾ ᧘᧔ನ ᮠ۫ܙू ฉॎͯረ
图 6 数据增强前后对比
Fig. 6 Comparison before and after data enhancement