
Page 90 - 《应用声学》2025年第3期
P. 90
624 2025 年 5 月
2.7 泛化实验 在 Urbansound8K 数据集上取得了 95.14% 的准确
为了验证本文提出的模型具有一定的通用性, 率、94.71%的精确度、94.60%的召回率和94.65%的
选择Urbansound8K环境声数据集进行模型的泛化 F1-score。这些结果表明,尽管 Urbansound8K 数据
实验。UrbanSound8K 是一个用于环境声分类的公 集的声频样本在内容和结构上与 GTZAN 数据集
共数据集。该数据集包含来自城市环境中的 8732 存在差异,但本文方法仍然能够很好地适应这种
个声频样本,涵盖 10 个不同的环境声类别,分别 变化,并保持高水平的分类性能。此外本文方法在
为gun_shot、car horn、Siren、air_conditioner、chil- Urbansound8K 数据集上的表现与 GRU-AWS [37] 、
dren playing、dog_bark、Drilling、engine_idling、 GLAM [38] 、AST [20] 、PANN [39] 、CNN-A-LSTM [40]
Jackhammer、street_music。每个声频样本的持续 这些先进的声频识别方法相比也显示出了一定的
时间约为4 s,并且经过了人工标注。UrbanSound8K 优越性。实验数据表明,本文方法在准确率、精确
数据集可用于声频分类、环境声识别等机器学习和 度、召回率和F1-score上均高于这些模型,这进一步
信号处理任务。这个数据集对于研究城市环境噪 证明了本文方法的优越性和泛化能力。
声和开发智能环境监测系统具有重要意义。Urban-
3 结论
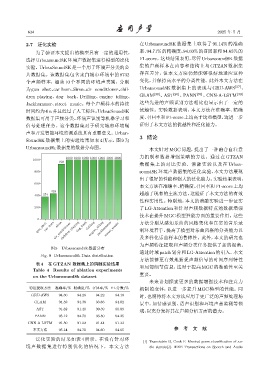
Sound8K 数据集上的实验结果如表 4 所示,图 9 为
Urbansound8k数据集的数据分布图。
本文针对 MGC 问题,提出了一种融合自注意
1000 1000 1000 1000 1000 1000 1000 力机制和数据增强策略的方法。通过在 GTZAN
1000
929
数据集上的对比实验、消融实验以及在 Urban-
800 sound8K 环境声数据集的泛化实验,本文方法展现
出了很好的性能和强大的泛化能力。实验结果表明,
600
本文方法在准确率、精确度、召回率和F1-score上均
429 超越了现有的主流方法,这验证了本文方法的有效
400 374
性和实用性。特别地,本文的消融实验进一步证实
200 了 LG-Attention 和针对声频数据特点的数据增强
技术在提升 MGC 模型性能方面的重要作用。这些
0 方法分别从感知乐曲的风格变化和真实的音乐录
engine_idling
siren
children playing
street_music
gun_shot car horn air_conditioner dog_bark drilling jackhammer 制环境着手,提高了模型对乐曲风格的分类能力以
及多样化乐曲样本的鲁棒性。此外,本文的研究也
为声频特征提取和声频分类任务提供了新的视角。
图 9 Urbansound8k 数据分布
通过时域 patch 划分和 LG-Attention 的引入,本文
Fig. 9 Urbansound8k Data distribution
方法能够更有效地捕捉声频信号的时间序列特性
表 4 在 GTZAN 数据集上的消融实验结果
和局部细节信息,这对于提高 MGC 的准确性至关
Table 4 Results of ablation experiments
重要。
on the Urbansound8k dataset
未来计划探索更多的数据增强技术和注意力
特征提取方法 准确率/% 精确度/% 召回率/% F1-分数/% 机制的变体,以进一步提升 MGC 模型的性能。同
GRU-AWS 94.30 94.26 94.22 94.18 时,也期待将本文方法应用于更广泛的声频处理场
GLAM 94.59 94.38 93.66 94.02
景中,如情感识别、语声识别和环境声音监测等领
AST 91.82 91.40 90.39 90.89
域,以充分发挥其在声频分析方面的潜力。
PANN 95.12 94.70 93.80 94.25
CNN-A-LSTM 91.50 91.22 91.44 91.33
本文方法 95.14 94.71 94.60 94.65 参 考 文 献
泛化实验的结果如表 4 所示。在没有针对环
[1] Tzanetakis G, Cook P. Musical genre classification of au-
境声数据集进行特别优化的情况下,本文方法 dio signals[J]. IEEE Transactions on Speech and Audio