
Page 46 - 201901
P. 46
42 2019 年 1 月
夫链划分为多个能量环,每个能量环D j 定义如下: RBM 的预训练仅仅为了使得 DBN 获得一个
较好的初始权重,避免训练时陷入局部最优 [14] 。为
D j = {(v, h) : E(v, h) ∈ [H j , H j+1 ]} ,
了使得 DBN 能更好地应用于音素识别,还需要针
j = 1, · · · , d. (12)
对目标输出进行监督训练。其输出目标为语音内的
接着在能量环内执行交换,而是否交换的依据 中间帧所对应的 HMM 状态。训练的损失函数为交
类似于公式 (10),不同的是此处的能量差应为同一 叉熵,通过方向传播算法获得网络的最终权值。
能量环内的两条链的能量差。实际中交换的次序是
从高温向低温执行的。此外由于在训练时 RBM 的 4 实验结果分析
参数是动态改变的,所以这些状态能量也是动态的,
实际操作中我们只要在训练 RBM 前设定好能量环 4.1 实验配置
的数量d即可。 本文实验在 TIMIT 语料库上进行,选择 462 个
最后经过多次循环采样、交换,最终将t 1 = 1温 说话人的 3296 个语句为训练集,选择 TIMIT 的核
度下的采样值用于 RBM预训练模型参数 θ,并采用 心测试集 (24 个说话人的 192 个语句) 作为测试集。
并行回火获取的目标采样值可使 RBM 训练获得较 语音信号使用 Hamming 窗处理,帧长 25 ms,帧移
好的应用效果。 10 ms,预加重系数为0.97。声学特征参数使用13阶
梅尔频率倒谱系数(Mel-frequency cepstrum coeffi-
3 基于RBM的深信度网络 cients, MFCC),以及其一阶、二阶差分系数,最终使
得每帧语音含有 39 维特征参数。RBM 的训练使用
在训练好一个 RBM 后,其隐层单元状态可以
8 条吉布斯链。预训练时的学习率为 0.001。监督学
作为训练下一个 RBM 的数据,所以该 RBM能够学
习中的学习率为0.0001,以Adam为优化器。
习到第一个 RBM 隐层单元之间的依赖性。这一过
程可以一直重复下去,直到产生所需要的非线性特 4.2 参数性能分析实验
征检测器的层数,层数越多统计数据结构也就越复
图 2 给出了隐层单元数为 1024 时,隐层数与帧
杂。将多个 RBM 堆叠起来就能产生一个多层生成
数对识别结果的影响。从图2中可以看出,随着隐层
模型 ——深信度网络 (DBN)。虽然单个 RBM 是间
数量和输入帧数的增加,识别性能有明显改善。其
接模型,但由它产生的 DBN 是一个混合生成模型。
中隐层数量的增加提高了网络对非线性函数的拟
DBN 的最上面 2 层是无向链接,其他层是自顶向下
合能力,而帧数的增加则代表了输入上下文信息量
的有向链接。获得 DBN 之后,在其顶层之上,再增
的增加。当 DNN 的隐层数为 4、输入帧数为 15 时,
加一个 softmax 输出层,输出每种音素对应的概率
取得了最佳识别性能。说明隐层数量的增加并不会
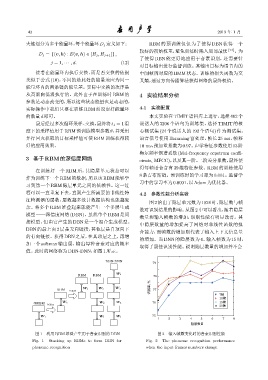
值。此时的网络称为DBN-DNN,如图1所示。
DBN-DNN
79
RBM RBM W 4 78
គѿဋ/%
RBM copy W 3 W 3 W 3 77
7ࣝ
11ࣝ
GRBM copy W 2 W 2 W 2 76 15ࣝ
21ࣝ
75
W 1 W 1 W 1
1 2 3 4 5 6 7 8
ᬥࡏᄬ
图 1 利用 RBM 堆叠产生用于音素识别的 DBN 图 2 输入帧数变化时的音素识别性能
Fig. 1 Stacking up RBMs to form DBN for Fig. 2 The phoneme recognition performance
phoneme recognition when the input frames numbers change