
Page 47 - 201901
P. 47
第 38 卷 第 1 期 阴法明等: 连续音素的改进深信度网络的识别算法 43
无限度地提高识别率,因为随着层数的增加,会导致 右,因为通过等能量划分后,相邻温度下的状态交换
梯度消失等问题 [15] 。同样输入信息的增加也不会 率提高了,进而提高了最终的识别率。由此说明在
无限度地改善系统性能,一方面是因为时间跨度较 没有增加计算量的情况下,本文对并行回火算法的
大的两帧语音数据之间的相关性较小,甚至有可能 改进在音素识别应用上是有效的。
从一个音素所在时间蔓延到另一个音素时间,导致 79
识别率下降;另一方面是当网络参数确定后,DNN
78
对于这些特征的区分能力是有限的。如图2 中15帧
77
语音与21帧语音所对应的识别率曲线图所示。
图 3 给出了输入帧数固定为 11 帧,隐层单元数 76
对识别结果的影响。从图3中可以看出,当隐层数固 គѿဋ/% 75
定时,增加隐层单元数可以提高音素识别性能。当 74 ஈᤉPT
隐层单元数较少时,通过增加隐层数量能有效提高 CD
73 PCD
识别性能,但当隐层数过多时,这种改善效果就显得 PT
72
非常有限。这表明隐层单元数在一定程度上决定了 1 2 3 4 5 6 7 8
ᬥࡏᄬ
网络最终的识别率。实际中,过多的隐层单元数和
隐层数会带来庞大的时间开销,而带来的性能改善 图 4 不同训练算法的音素识别性能
却是有限的,所以往往需要折中考虑参数配置。 Fig. 4 Phoneme recognition performance of dif-
ferent training algorithms
78 5 结论
本文首先研究分析了 RBM 的学习原理,在并
77
គѿဋ/% 行回火算法的基础之上,根据模型分布所得的样本
能量,进行等能量划分,以提高相邻温度链之间的交
76
1024ӭЋ 换率,进而提高模型期望的计算精度,训练出较好的
512ӭЋ
RBM。然后将 RBM 组成 DBN 应用于音素识别中,
75
实验表明,由该方法训练所得的 RBM 可以有效提
1 2 3 4 5 6 7 8 高最终识别率。
ᬥࡏᄬ
图 3 隐层单元数不同时的音素识别性能
参 考 文 献
Fig. 3 Phoneme recognition performance with dif-
ferent number of hidden layer nodes
[1] Saeb A, Razzazi F, Babaei-Zadeh M. A fast phoneme
recognition system based on sparse representation of test
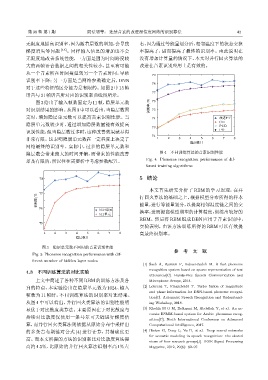
4.3 不同训练算法的对比实验
utterances[C]. Hands-Free Speech Communication and
上文中简述了各种不同 RBM 的训练方法及各 Microphone Arrays, 2014.
自的特点,本实验给出在隐层单元数为 1024、输入 [2] Lohrenz T, Fingscheidt T. Turbo fusion of magnitude
and phase information for DNN-based phoneme recogni-
帧数为 11 帧时,不同训练算法的识别率对比结果。
tion[C]. Automatic Speech Recognition and Understand-
从图 4 中可以看出,并行回火类算法的识别性能明 ing Workshop, 2018.
显优于对比散度类算法。主要原因在于对比散度与 [3] Khelifa M O M, Belkasmi M, Abdellah Y, et al. An ac-
curate HSMM-based system for Arabic phonemes recog-
持续对比散度仅使用一条马尔可夫链进行梯度估
nition[C]. Ninth International Conference on Advanced
算,而并行回火类算法则依据从原始分布中采样出 Computational Intelligence, 2017.
的多条吉布斯链对公式 (4) 进行计算,其精确度更 [4] Hinton G, Deng L, Yu D, et al. Deep neural networks
for acoustic modeling in speech recognition: the shared
高。而本文所提的方法的识别率比对比散度算法提
views of four research groups[J]. IEEE Signal Processing
高约 4.5%,比原始的并行回火算法识别率高 1% 左 Magazine, 2012, 29(6): 82–97.