
Page 162 - 《应用声学》2022年第4期
P. 162
660 2022 年 7 月
从 表 2 中 可 以 看 出, 基 于 WE 代 价 函 数 的 的 STOI 得分相同,二者处理后的语声可懂度基本
LSTM 单通道语声增强算法取 p = −0.5 时在各 一致。p = −0.5 时的 WE 代价函数与 MSE 代价函
个 SNR 条件下都取得了最优性能。当 p < −0.5 或 数的 STOI 得分也基本相同,结合表 2 的实验结果
者 p > −0.5 时,PESQ 结果变差,特别是 p = −1.9 表明,WE 代价函数能够在保证语声可懂度的同
和 p = 2 的场景。一方面,根据式 (10),当 p 的绝对 时大大提高处理后信号的语声质量。STOI 代价函
值较大时,WE代价函数的取值动态范围会变大,导 数的 STOI 得分与 MSE 代价函数相差不大,尤其是
致模型训练的收敛速度较慢,误差较大。另一方面, 在高信噪比场景下。但是表 2 中 STOI 代价函数的
此时代价函数对于噪声抑制和干净语声保留较为 PESQ 得分远远低于 MSE 代价函数。这是因为以
极端化,若p > 0,则干净语声保留较完整,但也会引 STOI 为代价函数的网络优化是以提高 STOI 得分
入更多残留噪声;若 p < 0,则噪声残留较少,但同 为目的,但是却忽略了语声质量指标,导致其PESQ
时会引入较大语声失真,二者均会导致整体语声质 得分较低。
量的降低。整体来看,p = −0.5 时的 WE 代价函数 为了测试不同代价函数在未见噪声场景下的
在不同 SNR条件下的平均 PESQ 得分比 MSE 代价 性能,从 NOISEX-92 数据库中选取 6 种噪声,与
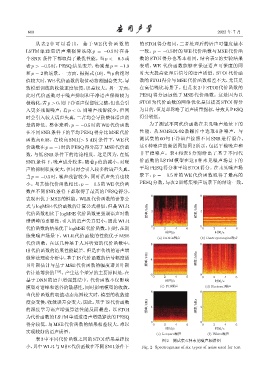
函数高 0.08。在较高 SNR(> 5 dB) 条件下,WE 代 测试集的 60 句干净语声按照不同 SNR 进行混合。
价函数在p = −1 时的 PESQ得分高于 MSE代价函 这 6 种噪声的频谱图如图 2 所示,包括平稳噪声和
数,与低 SNR 条件下的结论相反。这是因为,在低 非平稳噪声。表 4 和表 5 分别给出了基于不同代
SNR 条件下,噪声成分较多,随着 p 值的减小,对噪 价函数的 LSTM 模型在这 6 种未见噪声场景下的
声的抑制程度变大,但同时会引入较多的语声失真。 平均 PESQ 得分和平均 STOI 得分。在未见噪声场
当 p = −0.5 时,噪声残留较少,同时语声失真也较 景下,p = −0.5 时的 WE 代价函数取得了最高的
小。与其他代价函数相比,p = −0.5 的 WE 代价函 PESQ 分数,与表 2 训练集噪声场景下的结论一致。
数在不同 SNR 条件下都取得了最高的 PESQ 得分,
8 8
表现出优于 MSE的性能。WLR 代价函数的计算公
式与 logMSE代价函数的计算公式相似,但是 WLR
代价函数相比于 logMSE 代价函数更强调语声对数 ᮠဋ/kHz 4 ᮠဋ/kHz 4
谱谱峰的重要性,引入的语声失真更小,因此 WLR
代价函数的结果优于logMSE代价函数。同时,在训 0 0 2 4 6 0 0 2 4 6
ᫎ/s ᫎ/s
练集噪声场景下,WLR 代价函数的性能优于 MSE (a) Babble٪ܦ (b) Destroyerengine٪ܦ
代价函数。在这几种基于人耳听觉的代价函数中, 8 8
IS代价函数的结果性能最差。但是在传统的语声增
强算法理论分析中,基于 IS代价函数的信号幅度谱 ᮠဋ/kHz 4 ᮠဋ/kHz 4
贝叶斯估计与基于 MSE 代价函数的幅度谱贝叶斯
估计是等价的 [19] 。产生这个差异的主要原因是,在
0 0
0 2 4 6 0 2 4 6
基于 DNN 的语声增强算法中,代价函数不仅影响 ᫎ/s ᫎ/s
模型对谱峰和谱谷的敏感性,同时影响模型的收敛。 (c) F16٪ܦ (d) Factory1٪ܦ
8 8
当代价函数的取值动态范围较大时,模型的收敛速
度会变慢,收敛误差会变大,因此,基于IS代价函数
的深度学习语声增强算法性能反而最差。以 STOI ᮠဋ/kHz 4 ᮠဋ/kHz 4
为代价函数的LSTM单通道语声增强算法的PESQ
得分较低,与 MSE 代价函数的结果相差较大,难以 0 0 2 4 6 0 0 2 4 6
ᫎ/s ᫎ/s
实现较好的语声质量。
(e) Leopard٪ܦ (f) White٪ܦ
表 3 中不同代价函数之间的 STOI 结果差距较 图 2 测试集 6 种未见噪声频谱图
小,其中WLR与MSE代价函数在不同SNR条件下 Fig. 2 Spectrograms of six types of noise used for test