
Page 167 - 《应用声学》2022年第4期
P. 167
第 41 卷 第 4 期 程琳娟等: 人耳听觉相关代价函数深度学习单通道语声增强算法 665
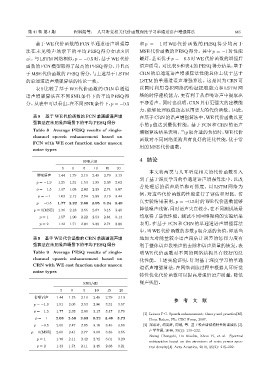
基于 WE 代价函数的 FCN 单通道语声增强算 和 p = −1 时 WE 代价函数的 PESQ 得分均高于
法在未见噪声场景下的平均 PESQ 得分如表 8 所 MSE 代价函数的 PESQ 得分。其中 p = −1 时性能
示。与LSTM网络相似,p = −0.5时,基于WE代价 最好,甚至优于 p = −0.5 时 WE 代价函数的增强后
函数的FCN模型取得了最高的PESQ得分,并且高 语声质量。对比表9 和表 4的PESQ得分结果,基于
于MSE代价函数的PESQ 得分,与上述基于LSTM CRN 的单通道语声增强算法性能总体上优于基于
的单通道语声增强算法的结论一致。 LSTM 的单通道语声增强算法。这是因为 CRN 可
表 9 比较了基于 WE 代价函数的 CRN 单通道 以同时利用卷积网络的特征提取能力和 LSTM 网
语声增强算法在不同 SNR 条件下的平均 PESQ 得 络的时序建模能力,更有利于从带噪语声中提取出
分。从表中可以看出,在不同SNR条件下,p = −0.5 干净语声。同时也说明,CRN 具有更强大的建模能
力,能够处理取值动态范围更大的代价函数。因此,
表 8 基于 WE 代价函数的 FCN 单通道语声增 在基于CRN 的语声增强算法中,WE代价函数以更
强算法在未见噪声场景下的平均 PESQ 得分
小的 p 值达到最优性能。基于 FCN 和 CRN 的语声
Table 8 Average PESQ results of single-
增强算法结果表明,当p 取合适的负值时,WE 代价
channel speech enhancement based on
函数对不同网络架构具有良好的泛化性能,优于常
FCN with WE cost function under unseen
用的MSE代价函数。
noise types
SNR/dB 4 结论
−5 0 5 10 15 20
本文将两类与人耳听觉相关的代价函数引入
带噪语声 1.44 1.75 2.10 2.45 2.79 3.13
到了基于深度学习的单通道语声增强算法中,以改
p = −1.9 1.25 1.31 1.54 1.95 2.33 2.62
善处理后的语声质量和可懂度。以 LSTM 网络为
p = −1.5 1.37 1.68 2.03 2.39 2.74 3.07
例,对这些代价函数的性能进行了评估和对比。仿
p = −1 1.63 2.12 2.54 2.89 3.19 3.44
真实验结果表明,p = −0.5 时的 WE 代价函数能够
p = −0.5 1.77 2.22 2.60 2.95 3.24 3.49
p = 0(MSE) 1.76 2.18 2.55 2.87 3.15 3.40 降低噪声残留,同时语声失真较小,在不同测试场景
p = 1 1.57 1.90 2.22 2.53 2.84 3.14 均取得了最优性能。测试不同网络架构的实验结果
p = 2 1.42 1.71 2.04 2.39 2.74 3.08 表明,在基于 FCN 和 CRN 的单通道语声增强算法
中,当WE 代价函数的参数p取合适的负值,即适当
表 9 基于 WE 代价函数的 CRN 单通道语声增 地加大对能量较小语声段估计误差的惩罚力度有
强算法在未见噪声场景下的平均 PESQ 得分 利于整体语声段噪声的去除和语声质量的恢复,表
Table 9 Average PESQ results of single- 明 WE 代价函数对不同的网络结构具有较好的泛
channel speech enhancement based on 化性能。上述实验证明,针对基于深度学习的单通
CRN with WE cost function under unseen
道语声增强算法,在网络训练过程中根据人耳听觉
noise types
特性优化代价函数可以提高增强后语声质量,降低
SNR/dB 噪声残留。
−5 0 5 10 15 20
带噪语声 1.44 1.75 2.10 2.45 2.79 3.13
参 考 文 献
p = −1.9 1.51 2.03 2.53 2.96 3.31 3.57
p = −1.5 1.77 2.33 2.80 3.17 3.47 3.70
[1] Loizou P C. Speech enhancement: theory and practice[M].
p = −1 2.03 2.50 2.89 3.22 3.48 3.72 Boca Raton, FL: CRC Press, 2007.
p = −0.5 2.00 2.47 2.85 3.16 3.43 3.66 [2] 郑成诗, 胡笑浒, 周翊, 等. 基于噪声谱结构特性的谱减法 [J].
声学学报, 2010, 35(2): 215–222.
p = 0(MSE) 2.00 2.41 2.77 3.08 3.33 3.55
Zheng Chengshi, Hu Xiaohu, Zhou Yi, et al. Spectral
p = 1 1.78 2.11 2.42 2.72 3.01 3.29
subtraction based on the structure of noise power spec-
p = 2 1.43 1.74 2.11 2.49 2.88 3.21 tral density[J]. Acta Acustica, 2010, 35(2): 215–222.