
Page 166 - 《应用声学》2022年第4期
P. 166
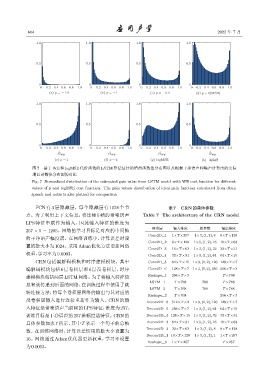
664 2022 年 7 月
1.0 1.0 1.0 1.0
0.5 0.5 0.5 0.5
0 0 0 0
0 0.2 0.4 0.6 0.8 1.0 0 0.2 0.4 0.6 0.8 1.0 0 0.2 0.4 0.6 0.8 1.0 0 0.2 0.4 0.6 0.8 1.0
(a) p=-1.9 (b) p=-1 (c) p=-0.5 (d) p=0(MSE)
1.0 1.0 1.0 1.0
0.5 0.5 0.5 0.5
0 0 0 0
0 0.2 0.4 0.6 0.8 1.0 0 0.2 0.4 0.6 0.8 1.0 0 0.2 0.4 0.6 0.8 1.0 0 0.2 0.4 0.6 0.8 1.0
G WE G WE G WE G WE
(e) p=1 (f) p=2 (g) logMSE (h) ࠄᬅϙ
图 7 基于 WE 和 logMSE 代价函数的 LSTM 算法估计的增益函数值分布图以及根据干净语声和噪声计算出的实际
增益函数值分布图的对比
Fig. 7 Normalized distribution of the estimated gain value from LSTM model with WE cost function for different
values of p and logMSE cost function. The gain values distribution of ideal gain function calculated from clean
speech and noise is also plotted for comparison
FCN 有 3 层隐藏层,每个隐藏层有 1024 个节 表 7 CRN 的具体参数
点。为了利用上下文信息,将连续 5 帧的带噪语声 Table 7 The architecture of the CRN model
LPS 特征串联作为输入,因此输入特征的维度为
257 × 5 = 1285。网络的学习目标是对应的中间帧 网络层 输入维度 超参数 输出维度
Conv2D_1 1×T ×257 1×3, (1, 2), 8 8×T ×128
的干净语声幅度谱。在网络训练中,计算误差时设
Conv2D_2 8×T ×128 1×3, (1, 2), 16 16×T ×63
置的批大小为 1024。采用 Adam优化方法更新网络
Conv2D_3 16×T ×63 1×3, (1, 2), 32 32×T ×31
权重,学习率为0.0003。 Conv2D_4 32×T ×31 1×3, (1, 2), 64 64×T ×15
CRN 包括编解码模块和时序建模模块。其中 Conv2D_5 64×T ×15 1×3, (1, 2), 128 128×T ×7
编解码模块包括 6 层卷积层和 6 层反卷积层,时序 Conv2D_6 128×T ×7 1×3, (1, 2), 256 256×T ×3
建模模块包括两层LSTM网络。为了将输入特征信 Reshape_1 256×T ×3 T ×768
LSTM_1 T ×768 768 T ×768
息有效传递到后面的网络,在训练过程中使用了跳
LSTM_2 T ×768 768 T ×768
转连接方法,将每个卷积层网络的输出与其对应的
Reshape_2 T ×768 256×T ×3
反卷积层输入进行连接重新作为输入。CRN 的输 Deconv2D_6 512×T ×3 1×3, (1, 2), 128 128×T ×7
入特征是带噪语声当前帧的 LPS 特征,维度为 257。 Deconv2D_5 256×T ×7 1×3, (1, 2), 64 64×T ×15
训练目标是干净语声的257维幅度谱特征。CRN的 Deconv2D_4 128×T ×15 1×3, (1, 2), 32 32×T ×31
具体参数如表 7 所示,其中 T 表示一个句子的总帧 Deconv2D_3 64×T ×31 1×3, (1, 2), 16 16×T ×63
Deconv2D_2 32×T ×63 1×3, (1, 2), 8 8×T ×128
数。在训练网络时,计算误差所用的批大小设置为
Deconv2D_1 16×T ×128 1×3, (1, 2), 1 1×T ×257
16。网络通过 Adam 优化器更新权重,学习率设置
Reshape_3 1×T ×257 T ×257
为0.0003。