
Page 164 - 《应用声学》2022年第4期
P. 164
662 2022 年 7 月
noisy LSTM(p=-0.5) LSTM(p=1) Bayesian(p=-0.5) Bayesian(p=1)
LSTM(p=-1) LSTM(p=0/MSE) Bayesian(p=-1) Bayesian(p=0/MSE)
4.0
4.5 4.0
3.5
4.0 3.5
CBAK 3.0 CSIG 3.5 COVL 3.0
2.5
3.0 2.5
2.0 2.5 2.0
1.5 2.0
1.5
-5 0 5 10 15 20 -5 0 5 10 15 20 -5 0 5 10 15 20
SNR/dB SNR/dB SNR/dB
(a) CBAK (b) CSIG (c) COVL
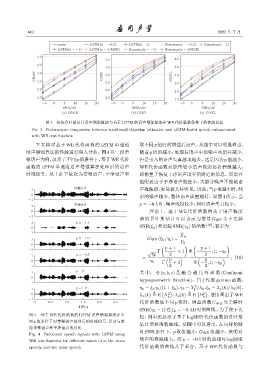
图 3 传统贝叶斯估计语声增强算法与基于 LSTM 的语声增强算法在 WE 代价函数条件下的性能比较
Fig. 3 Performance comparison between traditional Bayesian estimator and LSTM-based speech enhancement
with WE cost function
下文将对基于 WE 代价函数的 LSTM 单通道 取不同p值时的增强后语声。从图中可以明显看出,
语声增强算法的性能进行深入分析。图 4 以一段带 随着 p 值的减小,处理后语声中的噪声残留在减少,
噪语声为例,展示了不同 p值条件下,基于 WE代价 但是引入的语声失真越来越多。这是因为p值越小,
函数的 LSTM 单通道语声增强算法处理后的语声 WE 代价函数对能量较小语声段的惩罚程度越大,
时域信号。从上往下依次为带噪语声、干净语声和 即侧重于恢复干净语声谱谷值附近的信息。而谱谷
值附近由于干净语声能量小,大部分噪声不能被语
1 ᑖಚ䈝༠ 声掩蔽掉,更易被人耳听见。因此,当p值越小时,残
0
余的噪声越少,整体语声质量越好。如图 4 所示,当
-1
1 ᒢ߰䈝༠ p = −0.5时,噪声残留较少,同时语声失真较小。
0 理论上,基于 WE 代价函数的关于语声幅度
-1
谱的贝叶斯估计可以表示为增益 G WE 关于先验
1 p/֓⊲
SNR(ξ k )和后验SNR(γ k )的函数 [19] ,表示为
0
-1 ˆ
X k
p/֓⊲
1 G WE (ξ k , γ k ) =
Y k
0 ( ) ( )
p + 1 p + 1
-1
√ Γ + 1 Φ − , 1; −η k
1 p/֓⊲ η k 2 2
= ( ) ( ) , (16)
0 γ k p p
Γ + 1 Φ − , 1; −η k
-1 2 2
1 p/ 其 中, Φ (a, b, c) 是 融 合 超 几 何 函 数 (Confluent
0
hypergeometric function),Γ(·) 代表 gamma 函数,
-1
2
1 p/⊲ η k = ξ k γ k /(1 + ξ k ),γ k = Y /λ d ,ξ k = λ x (k)/λ d (k),
k
∆ [ ] ∆ [ ]
2
2
0 λ x (k) = E X ,λ d (k) = E D 。图 5 画出了 WE
k
k
-1
0 0.5 1.0 1.5 2.0 2.5 代价函数取不同 p 值时,增益函数 G WE 关于瞬时
ᫎ/s
SNR(γ k − 1)在ξ k = −5 dB时的曲线。为了便于比
图 4 基于 WE 代价函数的 LSTM 语声增强算法在不
较,图中还展示了基于 logMSE 代价函数的贝叶斯
同 p 值条件下对带噪语声处理后的时域信号,以及与原
估计增益函数曲线。从图中可以看出,在同样的瞬
始带噪语声和干净语声的对比
时 SNR 条件下,p 取值越小,G WE 值越小,表明对
Fig. 4 Enhanced speech signals with LSTM using
WE cost function for different values of p, the clean 噪声的衰减越大。而 p = −0.5 时的曲线与 logMSE
speech, and the noisy speech 代价函数的曲线几乎重合。基于 WE 代价函数与