
Page 165 - 《应用声学》2022年第4期
P. 165
第 41 卷 第 4 期 程琳娟等: 人耳听觉相关代价函数深度学习单通道语声增强算法 663
logMSE 代价函数的 LSTM 单通道语声增强算法在 接近理想值分布。这些代价函数在同样场景下的估
未见噪声场景下关于 CSIG、CBAK 和 COVL 评价 计误差方差如表 6所示,由表中可知,p = −0.5时的
指标的对比如图 6 所示。为了更加直观地进行展 WE 代价函数的方差最小,进一步验证了 p = −0.5
示,只选取了性能较好的p = −1和p = −0.5的WE 时,基于 WE 代价函数的 LSTM 单通道语声增强算
代价函数与 MSE 以及 logMSE 代价函数进行对比。 法性能最优。
图 6(a) 是在低信噪比情况下的结果,图 6(b)是在高 为了评估 WE 代价函数对其他网络结构的泛
信噪比情况下的结果。虽然p = −0.5的WE代价函 化性能,使用 FCN 和 CRN 对这些代价函数的性能
数与 logMSE 代价函数关于幅度谱的贝叶斯估计在 进行进一步测试。
理论上的增益函数曲线是重合的,但是在基于深度
5
学习的语声增强算法中,p = −0.5 的 WE 代价函数
在 CSIG、CBAK 以及 COVL 评价指标下的性能都 0
优于logMSE代价函数。 -5
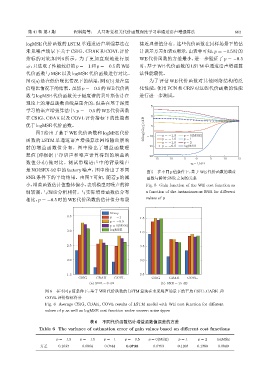
图 7 给出了基于 WE 代价函数和 logMSE 代价 20log(G WE )/dB p=-1.9 p=0(MSE)
函数的 LSTM 单通道语声增强算法网络输出层映 -10 p=-1.5 p=1
p=-1.0 p=2
射的增益函数值分布。图中给出了增益函数理 -15 p=-0.5 logMSE
想值 (即根据干净语声和噪声计算得到的增益函 -20
-15 -10 -5 0 5 10 15
数值分布) 做对比。测试带噪语声中的背景噪声 γ k-1/dB
是 NOISEX-92 中的 factory 噪声,图中给出了不同 图 5 在不同 p 值条件下,基于 WE 代价函数的增益
SNR 条件下的平均结果。由图 7 可知,随着 p 的减 函数与瞬时 SNR 之间的关系
小,增益函数估计值整体偏小,表明模型对噪声的抑 Fig. 5 Gain function of the WE cost function as
制较强,与理论分析相符。与实际增益函数值分布 a function of the instantaneous SNR for different
相比,p = −0.5 时的 WE 代价函数的估计值分布最 values of p
Noisy
3.5 p=-1 4.5
p=-0.5
p=0(MSE)
3.0 logMSE
4.0
2.5 3.5
2.0 3.0
1.5 2.5
CSIG CBAK COVL CSIG CBAK COVL
(a) SNR=0 dB (b) SNR=15 dB
图 6 在不同 p 值条件下,基于 WE 代价函数的 LSTM 算法在未见噪声场景下的平均 CSIG、CABK 和
COVL 评价指标得分
Fig. 6 Average CSIG, CBAK, COVL results of LSTM model with WE cost function for different
values of p as well as logMSE cost function under unseen noise types
表 6 不同代价函数估计增益函数值误差的方差
Table 6 The variance of estimation error of gain values based on different cost functions
p = −1.9 p = −1.5 p = −1 p = −0.5 p = 0(MSE) p = 1 p = 2 logMSE
方差 0.1037 0.0864 0.0744 0.0738 0.0753 0.1103 0.1380 0.0849