
Page 163 - 《应用声学》2022年第4期
P. 163
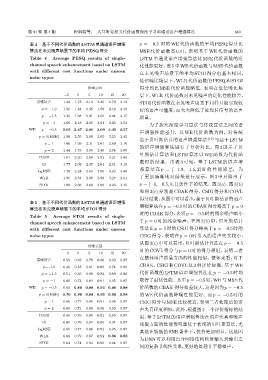
第 41 卷 第 4 期 程琳娟等: 人耳听觉相关代价函数深度学习单通道语声增强算法 661
表 4 基于不同代价函数的 LSTM 单通道语声增强 p = −0.5 时的 WE 代价函数的平均 PESQ 得分比
算法在未见噪声场景下的平均 PESQ 得分 MSE 代价函数高 0.11,表明基于 WE 代价函数的
Table 4 Average PESQ results of single- LSTM 单通道语声增强算法比 MSE 代价函数的泛
channel speech enhancement based on LSTM 化性能更好。表5中WE代价函数与MSE代价函数
with different cost functions under unseen
在未见噪声场景下的平均 STOI 得分也基本相同。
noise types
低信噪比场景下,WLR 代价函数的 PESQ 和 STOI
SNR/dB 得分均比 MSE 代价函数略低,表明在低信噪比场
−5 0 5 10 15 20 景下,WLR 代价函数对未见噪声的泛化性能较差。
带噪语声 1.44 1.75 2.10 2.45 2.79 3.13 STOI 代价函数在未见噪声场景下同样只能实现较
p = −1.9 1.30 1.34 1.35 1.56 2.10 2.49 好的语声可懂度,而大大降低了处理后信号的语声
p = −1.5 1.20 1.38 1.91 2.56 2.94 3.17
质量。
p = −1 1.66 2.18 2.65 3.04 3.33 3.54
为了探究深度学习算法与传统算法之间的语
WE p = −0.5 2.05 2.47 2.80 3.09 3.35 3.57
声增强性能差异,以 WE 代价函数为例,对传统
p = 0(MSE) 1.98 2.36 2.68 2.96 3.23 3.45
基于贝叶斯估计的语声增强算法 [19] 与基于 LSTM
p = 1 1.66 1.99 2.31 2.61 2.89 3.16
的语声增强算法进行了分析对比。图 3 展示了贝
p = 2 1.44 1.73 2.05 2.40 2.74 3.08
叶斯估计算法和 LSTM 算法以 WE 函数为代价函
COSH 1.81 2.20 2.58 2.92 3.21 3.48
数时的结果。由表 3 可知,基于 LSTM 的语声增
IS 1.77 2.09 2.37 2.64 2.91 3.19
强算法在 p = [−1.9, −1.5, 2] 时的性能较差,为
logMSE 1.78 2.24 2.62 2.95 3.23 3.48
WLR 1.95 2.35 2.69 2.98 3.27 3.51 了更加清晰地对结果进行展示,图 3 中只给出了
STOI 1.98 2.36 2.68 2.96 3.23 3.45 p = [−1, −0.5, 0, 1] 条件下的结果。图 3(a)、图 3(b)
和图 3(c) 分别是 CBAK 得分、CSIG 得分和 COVL
得分结果。从图中可以看出,基于贝叶斯估计的语声
表 5 基于不同代价函数的 LSTM 单通道语声增强
增强算法在p = −0.5时的CBAK得分略高于p = 0
算法在未见噪声场景下的平均 STOI 得分
时的CBAK得分,表明p = −0.5时的残余噪声略小
Table 5 Average STOI results of single-
于 p = 0 时的残余噪声。在图 3(b) 中,贝叶斯估计
channel speech enhancement based on LSTM
with different cost functions under unseen 算法在 p = 0 时的 CSIG 得分略高于 p = −0.5 时的
noise types CSIG 得分,表明在 p = 0 时引入的语声失真较小。
从图 3(c) 中可以看出,贝叶斯估计算法在 p = −0.5
SNR/dB
时的 COVL 得分与 p = 0 时的得分相近,表明二者
−5 0 5 10 15 20
在整体语声质量方面的性能相似。整体来看,对于
带噪语声 0.59 0.69 0.79 0.88 0.93 0.97
p= -1.9 0.49 0.55 0.61 0.66 0.74 0.82 CBAK,CSIG 和 COVL 这 3 种评价标准,基于 WE
代价函数的 LSTM 语声增强算法在 p = −0.5 时均
p = −1.5 0.51 0.56 0.68 0.82 0.89 0.92
p = −1 0.60 0.73 0.84 0.91 0.95 0.97 取得了最优性能。其中 p = −0.5时,WE 与MSE 代
WE p = −0.5 0.69 0.80 0.88 0.93 0.96 0.98 价函数的CBAK 得分相差较大,这是因为p = −0.5
p = 0(MSE) 0.70 0.80 0.88 0.93 0.96 0.98 的 WE 代价函数降噪性能更好。而 p = −0.5 时的
p = 1 0.66 0.77 0.85 0.91 0.95 0.97 CSIG 得分与 MSE 比较接近,表明二者处理后的语
p = 2 0.60 0.71 0.80 0.88 0.93 0.97 声失真程度相似。此外,根据图3三个评价指标的结
COSH 0.65 0.76 0.85 0.91 0.95 0.97 果,基于 LSTM 的语声增强算法在语声失真和噪声
IS 0.65 0.76 0.84 0.90 0.94 0.97
残留方面的性能都明显优于传统的贝叶斯算法,尤
logMSE 0.65 0.77 0.86 0.92 0.95 0.97
其是在较低的 SNR 条件下,优势更加明显。这是因
WLR 0.68 0.79 0.87 0.92 0.96 0.98
为 DNN 可以利用自身网络结构映射输入到输出之
STOI 0.64 0.74 0.83 0.90 0.94 0.97
间的复杂非线性关系,更好地处理非平稳噪声。