
Page 182 - 《应用声学》2025年第1期
P. 182
178 2025 年 1 月
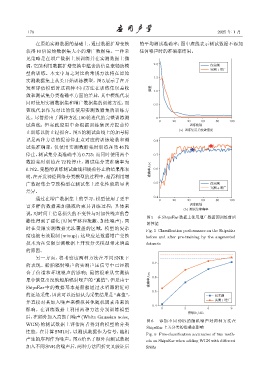
在原始实测数据的基础上,通过数据扩增变换 的平均测试准确率;图中虚线表示测试数据不添加
获得 10 倍原始数据集大小的增广数据集。一种常 任何噪声时的准确率结果。
见策略是在增广数据上预训练并在实测数据上微
调,它能利用数据扩增变换中蕴含的信息来辅助模 2.0 ̩ࠄ
ࠄ+ܙࣹ
型的训练。本文中与之对比的常规方法将在原始
1.5
实测数据集上从头开始训练模型。图5 展示了在开
发和评估模型时这两种不同方法在训练集误差收 ឨࣀ 1.0
敛和测试集分类准确率方面的差异,其中橙线代表
同时使用实测数据集和增广数据集的训练方法,而 0.5
蓝线代表作为对比的仅使用实测数据集的训练方
法。尽管给出了两种方法 100 轮迭代的完整训练测 0
0 20 40 60 80 100
试曲线,但实践应用中会根据训练集误差提前停 ᝫጷᣃ
(a) ᝫጷᬷឨࣀஆகৱц
止训练以防止过拟合。图 5 的测试曲线上的加号标
记是两种方法的提前停止点对应的训练轮数和测 0.8
试集准确率:仅使用实测数据集时训练在第 46 轮
停止,测试集分类准确率为 0.735;而同时使用两个 0.7
数据集时训练在 72 轮停止,测试集分类准确率为
0.762。完整的训练测试曲线和提前停止的结果都表 юᆸဋAcc 0.6
明,在开发神经网络分类模型的过程中,是否利用增
广数据集会导致模型在测试集上泛化性能的显著 0.5 ̩ࠄ
ࠄ+ܙࣹ
差异。
通过在增广数据集上的学习,模型使用了更丰 0.4 0 20 40 60 80 100
富多样的数据来加强或约束其训练过程;具体来 ᝫጷᣃ
(b) តᬷюᆸဋ
说,对时间上信息损失的不变性与对加性噪声的鲁
图 5 在 ShipsEar 数据上使用增广数据预训练前后
棒性得到了强化 (时间平移和掩蔽、加性噪声),同
的性能
时在受限实测数据无法覆盖的区域,模型的复杂
Fig. 5 Classification performance on the ShipsEar
度也被有效限制 (mixup);这些应是数据增广变换 before and after pre-training by the augmented
技术为在受限实测数据上开发分类模型带来增益 datasets
的原因。
另一方面,将考察这两种方法在不同 SNR 下
的表现。船舶辐射噪声的实测声压信号中已经耦 0.7
合了信道和环境噪声的影响;虽然很难从实测结
果中恢复出反映船舶辐射噪声的 “真值”,但是由于 юᆸဋAcc 0.6
ShipsEar 中的数据基本是船舶通过水听器附近时
0.5
的近场采集,因此可以近似认为采集结果是“真值”, ̩ࠄ
并直接对其加入噪声来模拟其他随机因素带来的 ࠄ+ܙࣹ
0.4
影响。在训练数据上利用两种方法分别训练模型 0 3 6 9
η٪උ/dB
后,在额外加入高斯白噪声(White Gaussian noise,
图 6 添加不同 SNR 的随机噪声对两种方法在
WGN) 的测试数据上评估两者得到的模型的分类
ShipsEar 上五分类的准确率影响
性能。在计算 SNR 时,以测试数据作为信号,随机
Fig. 6 Five-classification accuracies of two meth-
产生的序列作为噪声。图 6 给出了额外向测试数据 ods on ShipsEar when adding WGN with different
加入不同SNR的噪声后,两种方法四折交叉验证后 SNRs